Introduction
Machine learning and big data are becoming increasingly significant in the IT industry. As the world evolves, machine learning algorithms are being applied in various industries, including banking, healthcare, e-commerce, entertainment, and more. However, there is a dynamic relationship between machine learning and big data. Machine learning for big data is essential to train the algorithm to perform specific tasks. In addition, machine learning for big data plays a significant role in the performance of the algorithm.
Over the past few centuries, the progression of the internet has made data access easier and faster. In reality, data has become a support structure for big organizations and policymakers, even in government. However, if the right resources to process and store big data are not available, they will be misinterpreted.
Therefore, this guide will examine how machine learning for big data works. In addition, we shall consider the role of proxy servers in machine learning for big data.
What is Big Data?
Big data describes a huge amount of information collected, sorted, and analyzed for machine learning. Data can be in the form of observations, measurements, words, or numbers, usually in a format that computers can understand. Usually, big data consists of vast sets of data that can either be structured or unstructured.
What is Machine Learning?
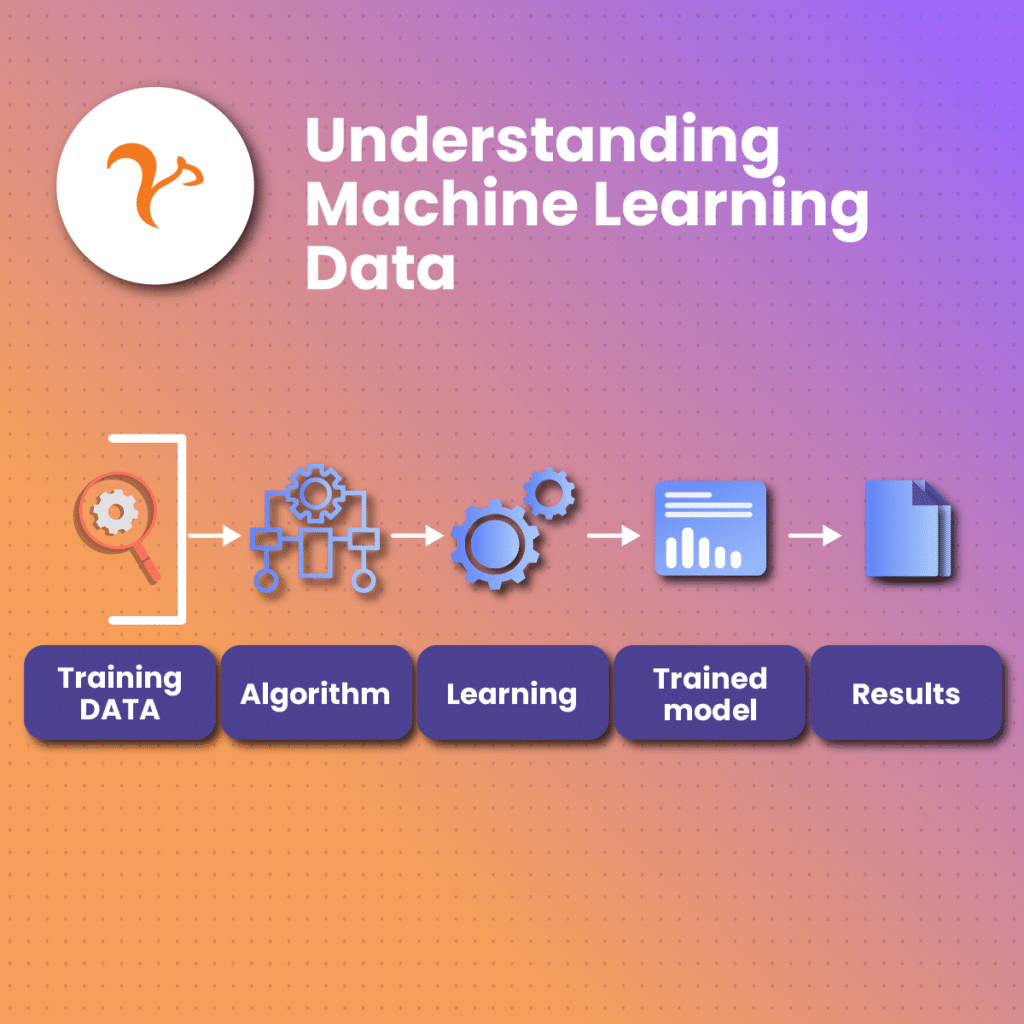
Machine learning involves self-learning algorithms that are constantly learning, especially with feedback from their assigned task. These algorithms often use pattern recognition to make predictions. For machine learning, big data is like exercise; higher data quality optimizes the predictive capability of the model.
In addition, machine learning often requires the use of programming languages, including JavaScript, Python, and Java. However, many developers prefer Python because it has a robust library with several tools.
Characteristics of Big Data in Machine Learning
The concept of machine learning for big data centers is “vast.” However, other attributes of big data that we must consider include:
Volume
We can attribute the advancement of technology to big data. However, the task of storing big data becomes a significant challenge for many organizations, as they may need to process terabytes and even exabytes of data.
In addition, data collection spans various sources, including social media sites, news platforms, e-commerce websites, and others. Subsequently, the need to store big data in an efficient manner is on a steady increase.
Velocity
Velocity is another term to be considered when discussing machine learning for big data. Sorting and processing data is a critical aspect of data flow management. Contrary to popular misconceptions, data is not static- it is collected, sorted, transformed, and analyzed at a high velocity. In addition, some applications of machine learning for big data demand high processing and analysis speed to maintain data flow.
Tools like RFID tags, smart sensors, and smart metering are often required to handle big data influx in real-time. Therefore, sorting, transforming, and storing such a large volume of data at a fast pace becomes a necessity.
Variety
Variety is another feature of machine learning for big data. It describes how different formats of data often come from various sources. Big data comes in structured, semi-structured, and unstructured formats. It can also be in the form of text, videos, emails, and transactions. Subsequently, organizing, managing, and storing big data may be a challenge due to the various formats.
Veracity
Veracity in machine learning for big data deals with inconsistencies and uncertainty in data. In machine learning for big data, veracity is not limited to accuracy but the reliability of the data source. In addition, it describes how meaningful the data is for analysis. Veracity in machine learning for big data involves removing duplicates, inconsistencies, and missing data.
Value
Value, when talking about machine learning for big data, refers to the usefulness of the dataset. Data can be in a structured or unstructured format, but it may not be useful, irrespective of the volume. Therefore, it becomes necessary to convert it into a useful format, which makes it easier to use and understand.
Visualization
Visualization is an important characteristic of machine learning for big data. Trying to comprehend the salient details from a large chunk of data may be too exhausting. Instead, representing the data using charts, graphs, and other methods of data visualization is a more efficient way to convey the key points.
Validity
In machine learning, big data needs to be valid. The dataset should match the performance of the model. A large dataset may be accurate but not valid if it does not significantly contribute towards the positive development of the machine learning algorithm.
Machine Learning for Big Data
Machine learning for big data is a combination of two worlds, machine learning and big data. Machine learning algorithms become more effective as the size of the training dataset increases. Therefore, machine learning for big data has two primary advantages; first, the algorithm helps us keep up with the continuous influx of big data. On the other hand, the volume and variety of big data aids machine learning as it helps algorithms learn and evolve.
Subsequently, when you feed big data into machine learning models, you can expect defined results such as analysis and pattern identification, which can help in predictive modeling. Many big organizations rely on machine learning for big data to automate several processes previously handled solely by humans.
Application of Machine Learning for Big Data
Here are some applications of machine learning for big data:
Market research
Businesses can rely on machine learning for big data to conduct market research and target audience segmentation. Understanding your target audience requires more than simple surveys and observation. This is where machine learning for big data comes into play- the algorithm uses big data to study and highlight patterns that help you understand your target audience.
Machine learning for big data is commonly used in ecommerce, entertainment, and advertising to identify target audiences, their pattern of activities, and preferences.
Recommendation engines
The recommendation engine is an excellent example of machine learning for big data. Ecommerce platforms like Amazon and streaming platforms like Netflix use the recommender system for big data that is powered by machine learning. The recommender system uses data from customer’s previous activities to predict possible future actions. Subsequently, this helps to provide a personalized effect which ultimately optimizes user experience.
Chatbots
Chatbots or Conversational User Interface is another popular application of machine learning for big data. Machine learning algorithms can leverage big data to adapt to customer preferences after several interactions. Alexa and Siri are two of the most known AI assistants, and they rely on machine learning for big data.
User modeling
User modeling is a form of target audience segmentation that is possible with machine learning for big data. The machine learning model studies user behavior and identifies specific patterns. An example of a company that leverages machine learning for big data is Facebook and Instagram. It makes intelligent suggestions on pages, ads, and communities based on previous patterns.
Ecommerce ad fraud
One of the biggest challenges in the ecommerce industry is ad fraud. Statistics show that about 10% to 30% of advertising activities are fraudulent. However, machine learning for big data can deal with this problem by recognizing patterns, assessing their credibility, and blocking any suspected fraudulent activities.
Optimizing Machine Learning for Big Data with NetNut
Proxies serve as an intermediary between your device and the internet and play a significant role in machine learning for big data. They are critical to ensuring data accuracy and optimizing privacy. In addition, in machine learning for big data, proxies assist in gathering large amounts of data from various regions, which increases the accuracy of predictions.
Therefore, it is not enough to randomly choose any proxy. It becomes critical to choose a reliable proxy service provider like NetNut.
Rotating proxies are ideal for optimized privacy and data accessibility. You can also use datacenter proxies to reduce bias, so you can gather data from various sources to promote data diversity. If you want a specialized mobile proxy solution, NetNut has got you covered.
Conclusion
In this guide, we have discussed the concept of machine learning for big data. Machine learning for big data is necessary to analyze vast data that is impossible for humans to handle effectively. Subsequently, we can rely on machine learning for big data to identify patterns and make accurate predictions.
We also examined some characteristics of machine learning for big data, including volume, veracity, value, velocity, validity, visualization, and variety. In addition, we discussed some applications of machine learning for big data, including chatbots, user modeling, ecommerce, and fraud detection, among others.
Finally, we uncovered the significance of proxies to machine learning for big data. Kindly contact us if you need to speak to an expert regarding the best proxy solution for you.
Frequently Asked Questions
What are the challenges of machine learning for big data?
Big data usually includes structured and unstructured data, which makes it hard to manage. Many organizations across various industries rely on big data. Here are some of the challenges of big data:
- Sharing
- Capturing
- Curating
- Transferring
- Sharing
- Storing
- Analyzing
- Visualization
What are some tips to get the best result from machine learning for big data?
Here are some tips to handle machine learning for big data:
- Data hygiene: Data hygiene is necessary in machine learning for big data. Poor data hygiene can produce results that cost a company several millions as well as their reputation.
- Know your goal: Another tip regarding machine learning for big data is knowing what you want to achieve. Focus on your identified problem statement to avoid being swayed by the social media hype surrounding machine learning for big data.
- Scaling tools: The use of scaling tools can optimize machine learning for big data. These tools increase our problem-solving capacity.
What are the differences between machine learning and big data?
|
Machine Learning |
Big Data |
|
Machine learning uses big data to make predictions. |
Big data is a large dataset that is often difficult to store and cannot be managed manually. |
|
Categories of machine learning include supervised, semi-supervised, unsupervised, and reinforcement learning. |
Categories of big data include structured, unstructured, and semi-structured data. |
|
Machine learning improves product recommendations, customer service, personal virtual assistance among many others. |
Big data is useful in various areas including healthcare, stock market analysis, environmental protection and others. |
|
In machine learning, the algorithm is fed with training data. |
Big data involves extracting raw material, looking for a pattern which helps in optimized decision making. |