Introduction
Machine learning models are heavily reliant on data. Therefore, it becomes critical to discuss machine learning training data. The absence of quality data can make a model useless regardless of the software used to build it. In other words, the output of a machine model depends on the input. As a result, the performance of a machine learning model can be suboptimal if it is trained with irrelevant, inaccurate, or inadequate data.
The most crucial element of machine learning is training data. However, to ensure optimal performance requires harmony between people, tools, and processes.
This guide will examine machine learning training data, how it works, the methods of training machine learning models, the roles of humans in the process, and FAQs.
What is Machine Learning?
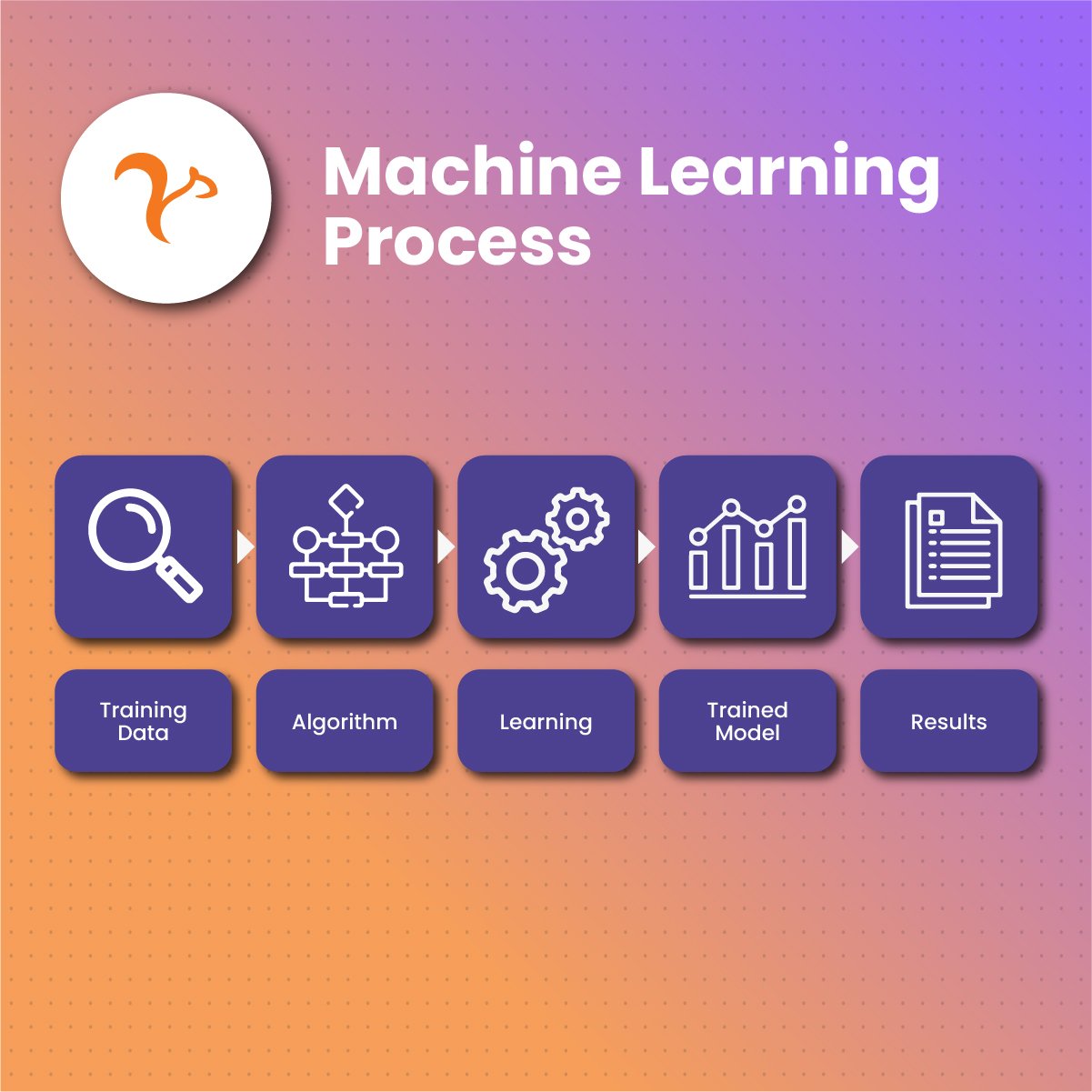
Machine learning is a subset of artificial intelligence that uses statistical techniques that allow computers to learn and make decisions without explicit programming. It is based on the precept that computers can use machine learning training data to learn and identify patterns, and make judgments with little human intervention.
Machine learning is a learning process to make machines more human-like in their responses, decisions, and behavior. This is possible with machine learning training data that allows them to learn and develop knowledge on various subjects. Data is fed into these machines, and various algorithms are used to build machine language models to train machines. The algorithm used is based on the data type and the machine’s eventual functionality.
What is Machine Learning Training Data?
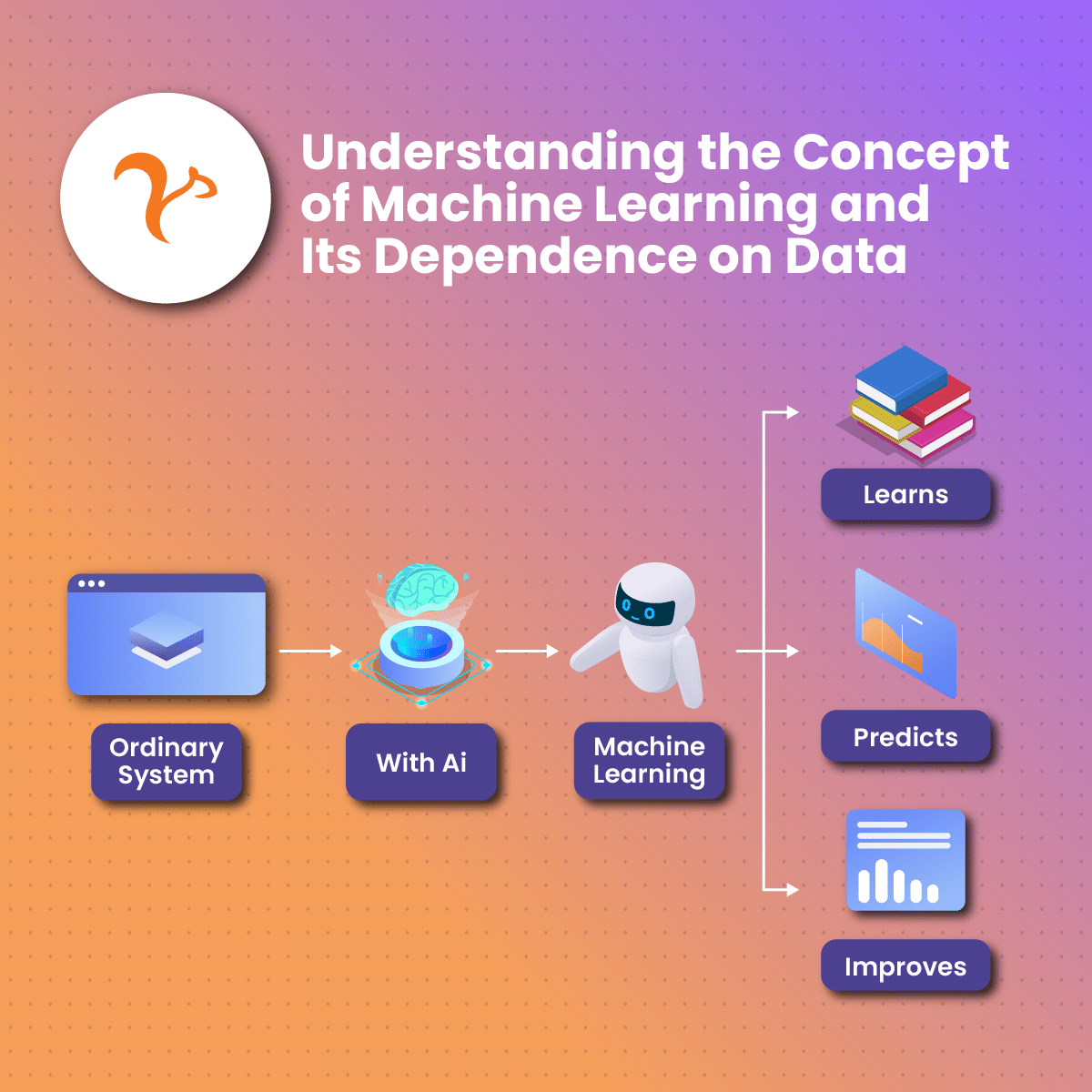
Machine learning training data is the data that is used to train a machine learning model. Although the aim is to give the machine model some autonomy, it still requires human intervention. Humans have to analyze the machine learning training data and ensure it is of high quality before feeding it into the model.
In other words, machine learning training data is the information that the system will use to process requests and provide meaningful feedback. We can compare machine learning training data to toddlers who need to be guided on how to behave and react to situations in their environment. For example, if you teach a child to say “thank you “every time they receive something from others, they will be conditioned to do so, even in public. Subsequently, the machine learning training data is a form of conditioning. Hence, it performs in a specific way.
The machine learning training data is fed to the algorithm, which allows them to identify patterns and make predictions on a certain task.
Method of machine learning
In machine language, the training data depends on whether you use supervised, unsupervised, or semi-supervised Learning Algorithms.
Supervised learning: Regarding supervised learning, the machine learning training data consists of labels that can be used to train the model to make predictions and provide solutions. Subsequently, it involves humans choosing the data features as well as labeling so the machine can detect outcomes.
Unsupervised learning: On the other hand, for unsupervised learning, the machine learning training data consists of unlabeled data. In this case, inputs are not tagged with corresponding outputs. These unlabeled data are unprocessed without tags. Therefore, the machine models must find the patterns from the machine learning training data to make meaningful predictions.
Meanwhile, the machine model accuracy predictive capacity depends on the machine learning training data type. Therefore, the model’s performance reflects the quality of machine learning training data.
Semi-supervised learning: Undoubtedly, labeling machine learning training data is great. However, the process of machine learning training data collection, refining, and labeling may take time and effort. This is where semi-supervised learning comes in. It is a hybrid method that uses both labeled and unlabeled data. Combining supervised and unsupervised learning optimizes data accuracy and reduces the time required to train a machine model.
Semi-supervised learning works with a small amount of labeled machine learning training data, which is used to annotate the larger dataset. Once the unlabeled data are annotated through this method, you can train the model as desired.
Therefore, semi-supervised machine learning training data depends on labeled data and the humans to do it. However, it differs from supervised learning because it requires less labeled data. As a result, the training and annotating process becomes optimized for increased efficiency.
How Does Machine Learning Training Data Work?
In machine learning, training data is required to expose the model to information it can use to provide outcomes. The features and quality of machine learning training data determine the algorithm’s accuracy in identifying patterns and predicting answers.
First, you must collect a large amount of raw machine learning training data. The data specialists will process, sort, and label the data before it is introduced to the algorithm. This enriched data is then fed to the machine learning model.
Subsequently, the accuracy of the model is assessed. Depending on the output, machine learning training data can be optimized to ensure data accuracy. Human effort is required for iteration and refinement at this stage before the machine learning training data is fed to the algorithm.
Furthermore, your machine learning model is as good as the data you use to train it. For example, an algorithm trained with 1000 datasets from one country will pale in comparison to one that received 50,000 datasets from 50 countries. Therefore, consider more volume and diversity of machine learning training data to optimize your algorithm functionality.
Characteristics of Machine Learning Training Data
In machine learning, training data must be:
Large
Machine learning training data must be large enough to cover numerous aspects of the problem. In other words, the larger the data size, the more accurate predictions the model can make. However, high variance can cause overfitting, which means the model has to go through several unnecessary pieces of information to provide accurate results. On the other hand, insufficient machine learning training data can lead to low variance and bias.
Therefore, the goal is not to feed the model as much information as possible with total disregard for its use case. Instead, machine learning training data should contain adequate information to cover the problem without introducing unnecessary noise that interferes with processing speed.
Labeled and annotated
A characteristic of quality machine learning training data is that it should be well-labeled and annotated. This often requires experienced data labellers with domain knowledge who can make labeling decisions required for the model. In addition, the annotations must be properly applied in machine learning training data. Therefore, specialized labeling skills may be required for complex tasks, including LiDAR, polygon annotation, or pixel segmentation.
Representative and unbiased
Another characteristic of quality machine learning training data is that it must represent the information required. In addition, machine learning training data must be unbiased- the public does not fondly receive biased data. It could affect the adoption of the machine model.
When machine learning training data is biased, it could lead to regulatory or legal issues. Many machine models have failed due to inappropriate representation and bias. A typical example is Amazon’s recruitment AI that prejudiced women.
Bias and need for more diversity in machine learning training data present technical and ethical challenges. However, most of these challenges are not adequately addressed. Therefore, teams building algorithm models must actively pay attention to these issues.
Compliance with privacy laws
In machine learning, training data must comply with privacy laws and regulations. Data protection laws like the GDPR restrict the use of data that contain personal identifying information for public use. In addition, it regulates industries like healthcare and finance that deal with customers’ sensitive information.
Why Humans are Involved with Machine Learning Training Data?
Humans play a crucial role in machine learning training data because the information needs to be checked, sorted, and preprocessed. As mentioned above, if you are using a supervised learning approach, it requires human intervention.
Usually, a data scientist is responsible for labeling, sorting, and organizing the data. Depending on the machine model used, the data scientist may need to format the data. Subsequently, the machine model can process the data faster because it does not have to go through data that may not be necessary for its function.
Data preparation also involves some form of data augmentation, including changing picture orientation, blurring, translation, and more. The purpose of data augmentation is to provide additional machine learning training data. Therefore, it optimizes the chance of getting reliable responses from the model.
In addition, data scientists may need to analyze the first set of responses. This step is necessary to ascertain the performance of the model. It informs the decision to provide more machine learning training data, or the model can go through the validation phase. Therefore, if the outcome differs from what was expected, you may need to modify some parameters or use different machine learning training data.
Factors that Affect Machine Learning Training Data
Three factors can affect the quality of machine learning training data, including people, tools, and the process. Let us examine these factors individually.
People
The quality of machine learning training data begins with the people involved. Skills and relevant experience determine the quality of work that people deliver. Therefore, worker assessment is critical and may significantly affect the quality of machine learning training data for models. Assessment allows you to select individuals better suited for the role, increasing the chance of optimized productivity.
In addition, people require regular training to enhance performance. Sometimes, customized training may be necessary depending on the project’s complexity. This additional training ensures the workers have the necessary skills to work quickly without affecting the overall quality of the result.
Tools
Another factor that can affect the quality of machine learning training data is tools. Regardless of project type, appropriate tools facilitate workers’ efficiency. Therefore, the quality and productivity will inherently suffer if you use manual tools instead of automated technology.
In addition, using inappropriate tools can significantly slow down the task or make machine learning training data more expensive. Subsequently, using the right technology reduces cost, increases speed, and enhances the quality of machine learning training data.
Tools provide a form of flexibility in gathering machine learning training data. In addition, tools make work faster so that workers can channel their time and efforts to other productive activities.
Process
The process also plays a significant role in machine learning training data quality. It should involve tight quality controls and precise specifications that lead to high quality. A critical aspect of the process is communication and collaboration. With machine learning training data, the process must be optimized to meet the specific goals within the required period.
You can either have an in-house team or an external expert to oversee the handling of machine learning training data. However, if you have an in-house team, find experts to review your existing processes and modify them as needed for optimal performance.
In addition, iteration is necessary to ensure the quality of machine learning training data. This requires prompt communication with people who handle the data so they can provide feedback that optimizes training the machine model.
Proxies for Machine Learning Training Data
One of the challenges to machine learning training is obtaining a large amount of data. The reality is that storing and formatting large amounts of machine learning training data can be quite expensive. In addition, the required amount of data may be inaccessible for several reasons. This is where proxy servers come in. They act as an intermediary that hides your network identity and IP address.
Therefore, many businesses use rotating proxies for activities like web data extraction. NetNut Proxies are an ideal solution because they provide privacy and enhance data accessibility. Subsequently, you can change your IP address as often as you want and access data from any corner of the world while avoiding limitations associated with your IP address.
The Internet Service Provider (ISP) often provides the IP address, and anyone can see it. Anyone on the internet can use your IP address to track your devices’ location, operating system, software, and hardware components. However, proxy servers allow you to access data from anywhere in the world while maintaining your privacy.
Another benefit of using datacenter proxies is bias reduction. Proxies enable you to gather data from various sources across the globe, which ensures diversity. As a result, the machine model can provide objective outcomes regarding various topics.
Conclusion
This guide has examined machine learning training data and its role in the accuracy of learning models. It usually involves preprocessed and annotated data that you can feed into your machine-learning model. Machine learning training data methods could be supervised, unsupervised, or semi-supervised.
Collecting large volumes of data can be challenging due to privacy concerns and location restrictions. Therefore, you need to choose a reliable proxy provider like NetNut to optimize the process of machine learning training data collection.
After collecting the data, human efforts are required to process and annotate the machine learning training data before using it to train the algorithm. Remember that the accuracy of your model depends on the quality of the machine learning training data. Therefore, ensure that large datasets from various locations are obtained to minimize any bias in its outcome.
If you have questions about choosing the best proxy solution for your data collection needs, kindly contact us.
Frequently Asked Questions
How much machine learning training data is required?
This is a critical question regarding machine learning training data. However, there is yet to be a concrete mathematical solution to this problem. However, since performance is affected by data quality, the more quality data the model has to learn from, the better.
Furthermore, the degree of complexity of the problem and the algorithm significantly influences the amount of machine learning training data. To ensure the model works as expected, you can feed it the data you have gathered and test its performance.
Source of machine learning training data
There are two main sources of machine learning data– open & public, and government data sources.
Open & public source describes machine learning training data that can be used, reused, and circulated without limitations. In other words, this machine learning training data source is not regulated by patents, copyright or other forms of legal control. Therefore, it is your duty to ensure regulatory and legal compliance of the machine model. While numerous public and open datasets exist, many are unsuitable for use as machine learning training data.
The government dataset is another source of machine learning training data. Many countries offer this data, including Singapore, the US, Australia, and the UK. These data include information on various sectors of the economy, including crime, health, policing, transport, law, and others.
What is the difference between testing data and machine learning training data?
In machine learning, training data, and testing data are both crucial to improving the model. However, machine learning training data aim to teach the model, while testing data assesses its efficiency.
In other words, machine learning training data is used to train a machine model to perform predefined tasks. On the other hand, testing data measures the accuracy of the machine model- this gives you an overview of its functionality, areas to improve, and how it uses the learning data to predict answers.