Introduction
In today’s digital age, where information is everywhere and data rules, web scraping has become a hot topic. But what exactly is web scraping? And is web scraping legal? Let us break it down.
Now, you might be thinking, “Why do I need to worry about whether web scraping is legal or not? Can’t I just grab the data I want and be done with it?” Well, not quite. Scraping data from websites without considering its legality can get you into legal issues.
Therefore, we are going to dive into the concept of web scraping and its legality. First, we shall start by examining web scraping, why it is crucial to understand if it is legal and what factors affect its legality.
What is Web Scraping?

Web scraping is like having a digital detective that gathers information from websites automatically. It involves using specialized software or tools to extract data from web pages. Instead of manually copying and pasting information, web scraping lets you automate the process, saving time and effort.
Purpose and Uses of Web Scraping
So, why do people scrape the web? Well, imagine you’re a business owner who wants to keep an eye on your competitors. With web scraping, you can gather data on their prices, products, and promotions without having to visit each website manually. This gives you valuable insights into the market and helps you make informed decisions.
In addition, web scraping is also helpful for researchers who need large amounts of data for their studies. Whether you’re analyzing social media trends, tracking stock prices, or studying online reviews, web scraping lets you collect data quickly and efficiently.
However, it’s not just businesses and researchers who benefit from web scraping. Developers use it to build applications that rely on up-to-date information from the web- like weather apps or travel websites. More so, journalists use it to uncover hidden stories buried deep within websites. Even hobbyists can use web scraping to gather information for personal projects or interests.
Difference between Manual Extraction and Automated Scraping
Now, you might be thinking, “Can’t I just copy and paste the information I need from websites manually?” Well, technically, you could. But manual extraction is like digging a hole with a spoon – slow, tedious, and not very efficient.
Automated scraping, on the other hand, is like using a shovel – it gets the job done faster and with less effort. Instead of manually clicking through web pages and copying data one by one, automated scraping tools do it for you. They can crawl through hundreds or even thousands of pages in a matter of minutes, collecting data much more efficiently than any human could.
So, while manual extraction might work for small tasks or one-time needs, automated scraping is the way to go for larger-scale projects and web data collection. Automated scraping is like upgrading from a spoon to a shovel – you’ll get the job done faster and with better results.
In summary, automated scraping is faster, more efficient, and essential for handling large amounts of data effectively.
Factors Affecting the Legality of Web Scraping
When it comes to web scraping, staying on the right side of the law involves navigating through various legal considerations. Let’s explain the key factors that can affect the legality of web scraping:
Terms of Service Agreements
Many websites have terms of service (TOS) or terms of use agreements that users must agree to before accessing their content. These agreements often outline the rules and restrictions regarding the use of the website, including any prohibitions or limitations on web scraping activities. It’s essential to carefully review the terms of service agreement of each website you intend to scrape to ensure compliance. Violating these terms could lead to legal consequences, such as breach of contract claims.
Copyright and Intellectual Property Rights
Copyright laws protect original works of authorship, including text, images, videos, and other content found on websites. Web scraping may involve copying and using copyrighted content without permission, which could constitute copyright infringement. It’s crucial to respect the intellectual property rights of website owners and obtain proper authorization before scraping or using copyrighted materials.
Purpose of Scraping
The legality of web scraping can also depend on the purpose for which the data is being scraped. If the scraped data is used for commercial purposes without permission, it may raise legal concerns, especially if it competes with the interests of the website owner. On the other hand, scraping data for personal, non-commercial use may be permissible in some cases, but it’s essential to ensure that you’re not violating any copyrights or terms of service agreements.
Ethical Considerations
In addition to legal considerations, web scraping also raises ethical concerns. Scraping large amounts of data from a website could put strain on its servers and impact its performance, potentially disrupting the user experience for other visitors. It’s essential to conduct web scraping activities responsibly and ethically, respecting the rights and interests of website owners and users. Avoid excessive scraping that could cause harm or inconvenience to website operators, and be mindful of the potential consequences of your scraping activities.
In summary, by understanding these factors, you can conduct web scraping activities responsibly and minimize the risk of legal issues or ethical concerns.
Best Practices for Legal Web Scraping
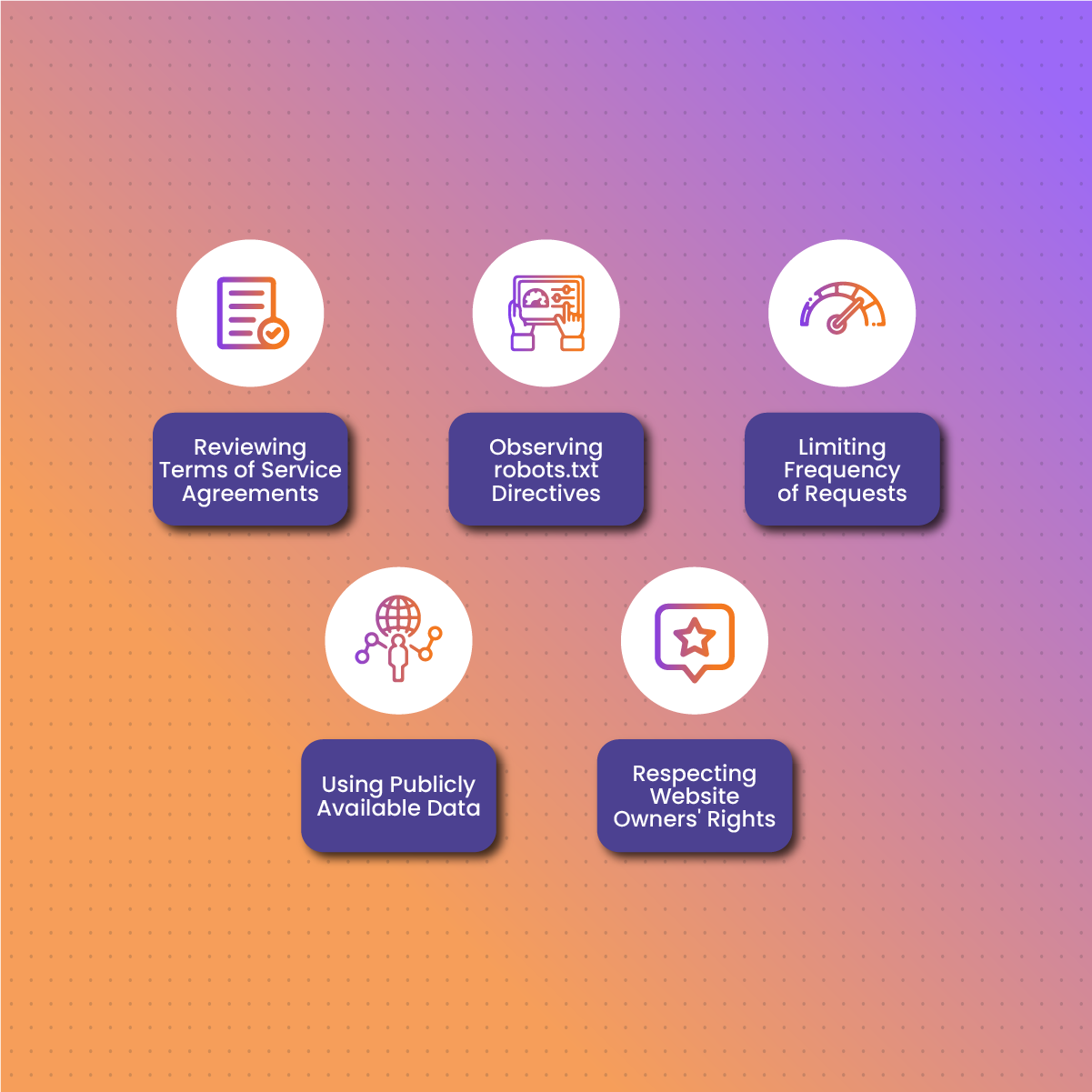
When it comes to web scraping, following best practices is essential to ensure that you’re conducting your scraping activities legally and ethically. Here are some tips to help you scrape the web responsibly:
Reviewing Terms of Service Agreements
Before scraping any website, take the time to review its terms of service (TOS) or terms of use agreements. These agreements often outline the rules and restrictions regarding the use of the website, including any prohibitions or limitations on web scraping activities. If the TOS explicitly prohibits scraping or imposes certain conditions on its use, it’s crucial to respect these terms and refrain from scraping the website.
Observing robots.txt Directives
Pay attention to the website’s robots.txt file, which is a standard used by websites to communicate with web crawlers and scrapers. The robots.txt file may contain directives that specify which parts of the website are open to crawling and scraping and which parts are off-limits. It’s important to respect these directives and refrain from scraping any content that the website owner has indicated should not be accessed by web crawlers.
Limiting Frequency of Requests
Avoid sending too many requests to a website within a short period, as this could be interpreted as a denial-of-service attack and may lead to legal action. Be mindful of the website’s server capacity and performance, and adjust the frequency of your scraping requests accordingly. Consider implementing delays between requests to avoid spamming the website’s servers. Also, this would help bypass online proxy blocks or be banned.
Using Publicly Available Data
Stick to scraping data that is publicly available and avoid accessing restricted or private information. Respect the boundaries set by website owners and refrain from attempting to access password-protected or confidential areas of a website. Focus on collecting data that is intended for public consumption and avoid scraping sensitive or proprietary information without permission.
Respecting Website Owners’ Rights
Above all, respect the rights and interests of website owners and operators. Avoid scraping data in a manner that disrupts the normal operation of the website or that infringes upon the intellectual property rights of the website owner. Be transparent about your scraping activities and provide clear attribution if you use scraped data in any public-facing projects or publications. Communicate openly with website owners and seek permission if you are unsure about the legality or appropriateness of your scraping activities.
Legal Alternatives to Web Scraping
While web scraping can be a valuable tool for gathering data from the web, it’s essential to consider legal alternatives. This is crucial especially if the web scraping process may raise concerns about legality or ethics. Here are some legal alternatives to web scraping:
Utilizing Publicly Available APIs
Many websites and online platforms offer Application Programming Interfaces (APIs) that allow developers to access and retrieve data in a structured and standardized format. APIs provide a legal and sanctioned method for obtaining data from websites and typically come with terms of service agreements that outline how the data can be accessed and used. By utilizing publicly available APIs, you can access data from websites in a legal and ethical manner without resorting to scraping.
Obtaining Data Through Licensed Third-Party Providers
Another legal alternative to web scraping is to obtain data from licensed third-party providers or data vendors. These providers offer access to curated datasets and databases that have been collected, aggregated, and processed from various sources. By purchasing access to these datasets, you can obtain the data you need legally and without the risk of infringing upon the rights of website owners. Licensed third-party providers often offer customizable data solutions tailored to specific business needs and requirements.
Exploring Open Data Sources
Many governments, organizations, and institutions make data available to the public through open data initiatives and platforms. Open data sources provide access to a wide range of datasets on topics such as demographics, economics, health, and the environment. By exploring open data sources, you can find valuable data that is freely accessible and can be used for research, analysis, and application development. Open data promotes transparency, collaboration, and innovation by making information freely available to the public.
By utilizing these legal alternatives to web scraping, you can access data from the web in a manner that respects the rights of website owners, adheres to applicable laws and regulations, and promotes responsible data practices. Whether you’re a business, researcher, developer, or enthusiast, exploring these alternatives can provide access to valuable data without the legal risks associated with web scraping and data extraction.
Use of NetNut Proxies for Legal Web Scraping

Notably, web scraping, when done responsibly and ethically, can provide valuable insights and data for various purposes such as market research, competitive analysis, and academic studies. However, to conduct web scraping activities effectively and without encountering legal or technical obstacles, utilizing proxy service is often essential.
NetNut proxy service offers a range of solutions tailored to meet the diverse needs of web scrapers. This service provides reliable, secure, and high-performance proxies for legal web scraping. Here’s why you should consider using NetNut proxies for your web scraping processes:
Mobile Proxies
Mobile proxies emulate real mobile devices and IP addresses, making them ideal for scraping data from mobile-responsive websites and applications. With NetNut’s mobile proxies, you can access mobile-specific content and gather accurate data that reflects the user experience on mobile devices. Whether you’re extracting data from mobile apps, or location-based services, mobile proxies ensure seamless and reliable web scraping operations.
Static Residential Proxies
Static residential proxies offer dedicated IP addresses that remain constant and unchanged, providing stability and consistency for your web scraping activities. NetNut’s static residential proxies are ideal for scraping data from websites that require authentication, such as ecommerce platforms or subscription-based services. With static proxies, you can establish long-term connections to target websites and maintain a reliable scraping infrastructure without worrying about IP address changes or disruptions.
ISP Proxies
NetNut’s ISP proxies leverage a vast network of residential IP addresses assigned by Internet Service Providers (ISPs), ensuring high anonymity and legitimacy for your web scraping activities. By routing your scraping requests through ISP proxies, you can avoid detection and access geo-restricted or IP-restricted content without arousing suspicion. ISP proxies provide a robust and scalable solution for scraping data from a wide range of websites while maintaining a low risk of detection or blocking.
Rotating Residential Proxies
Rotating residential proxies offer unique IP addresses sourced from residential devices, providing high levels of anonymity and rotation capabilities for web scraping tasks. NetNut’s rotating residential proxies automatically rotate IP addresses at predefined intervals, allowing you to distribute scraping requests evenly and avoid IP bans or rate limits. With rotating residential proxies, you can scrape large volumes of data from diverse sources while maintaining a low profile and minimizing the risk of detection.
Benefits of using NetNut Proxies for Legal Web Scraping
Using NetNut Proxies for legal web scraping offers numerous benefits. This makes it a preferred choice for individuals and businesses engaged in data collection activities. Here are some of the key benefits of using NetNut Proxies:
- Anonymity and Privacy: NetNut Proxies provide high levels of anonymity, ensuring that your scraping activities remain confidential and secure. By masking your real IP address, NetNut Proxies protect your identity and privacy, reducing the risk of detection or tracking by target websites.
- Reliability and Stability: NetNut Proxies offer reliable and stable connections, minimizing downtime and disruptions during web scraping operations. With a vast proxy network and advanced infrastructure, NetNut ensures consistent performance and uptime, allowing you to scrape data efficiently and effectively.
- Versatility: NetNut Proxies offer a range of proxy types to suit different scraping requirements. Whether you need mobile proxies, static proxies, ISP proxies, or rotating residential proxies, NetNut provides versatile solutions tailored to meet your specific needs and preferences.
- Scalability: NetNut Proxies are designed to scale with your web scraping needs, allowing you to increase or decrease proxy usage as required. Whether you’re scraping data from a few websites or thousands of sources, NetNut’s flexible infrastructure can accommodate your scaling needs without compromising performance or reliability.
- Geographical Diversity: With NetNut Proxies, you can access IP addresses from various locations around the world, enabling geographically targeted scraping operations. Whether you need data from specific regions or countries, NetNut’s proxy network offers the geographical diversity required to access localized content and services.
- Compliance with Regulations: NetNut Proxies comply with legal and regulatory requirements, ensuring that your scraping activities adhere to applicable laws and regulations. By using NetNut Proxies, you can conduct web scraping operations ethically and responsibly, minimizing the risk of legal issues or compliance violations.
- Customer Support: NetNut provides comprehensive customer support to assist you with setting up and optimizing your scraping workflows. Whether you need technical assistance, advice on best practices, or troubleshooting help, NetNut’s support team is available to ensure a smooth and seamless experience.
In summary, whether you’re a small-scale or a large enterprise, NetNut Proxies provide the infrastructure and support needed to conduct web scraping activities efficiently, effectively, and ethically.
Conclusion
The digital world is always evolving with new innovations daily. For this cause, the web scraping practice has emerged as a powerful tool for accessing and extracting data from websites. In this article, we have uncovered the basics of web scraping legality.
In addition, we have learned that while web scraping itself is not completely illegal, its legality depends on various factors such as terms of service agreements, copyright laws, and ethical considerations.
By reviewing terms of service agreements, observing robots.txt directives, limiting the frequency of requests, and utilizing publicly available data, individuals and organizations can mitigate legal risks and conduct web scraping activities responsibly. Moreover, legal alternatives such as utilizing APIs, obtaining data from licensed third-party providers, and exploring open data sources offer viable options for data acquisition while staying within legal boundaries.
On a final note, as you navigate the web scraping process, remain vigilant, mindful, and proactive in upholding legal and ethical standards. By doing so, we can harness the potential of web scraping while safeguarding the integrity of digital ecosystems for generations to come.
Frequently Asked Questions and Answers
How do I get started with web scraping?
To get started with web scraping, you’ll need to choose a programming language or tool, familiarize yourself with HTML and CSS, and learn how to use scraping libraries or frameworks such as BeautifulSoup or Scrapy. There are many online tutorials and resources available to help you get started with web scraping.
Can I scrape data from ecommerce websites for price comparison purposes?
Scraping data from ecommerce websites for price comparison purposes may raise legal concerns, particularly if it violates the website’s terms of service or infringes upon intellectual property rights.
Can I scrape data from social media platforms?
Social media platforms typically have strict terms of service regarding scraping. It’s essential to review these terms and obtain permission before scraping data from social media sites.








