
Introduction
How to build a web scraper is a critical concept that revolves around collecting data from a website and saving it in your preferred format. Data scientists often need to collect large volumes of data that can inform critical decisions in an organization. However, manually copying data from the web and pasting it into an Excel sheet or Word document is not efficient. Therefore, it becomes crucial to discuss how to build a web scraper, extract the HTML code, parse the data, and store it.
Digital marketing is another field that can be significantly optimized with access to real-time data. As a result, brands need to understand the basic steps involved in how to build a web scraper. Python is one of the most popular web scraping languages with various libraries. Subsequently, it has become one of the best options to build a web scraper because it is simple and easy to use.
Regardless of your field, you may notice how significant data is to your operations. Therefore, this guide will provide step-by-step instructions on how to build a web scraper and the best Python libraries to use. In addition, we shall uncover a scalable alternative that you can use to collect data from any website without any form of limitation.
How Do Web Scrapers Work?
Web scrapers are programmed to automate the process of extracting data from websites. Since there are numerous web scrapers, there are bound to be some differences in how they work. However, this section will examine the basic steps associated with how web scrapers work.
Send an HTTP request to the website
The initial step involved in extracting data from websites with a web scraper is sending an HTTP request. The response determines if you can access the content of the website. When the scraper sends a request, the website can see your IP address and determine your location and other parameters. For example, if you are sending the request from a restricted location, the website will not approve the request.
Therefore, when the website approves your request, you can access the content on the page. On the other end, you may receive an error response if the website does not grant you access for various reasons. Subsequently, the first process of web scraping involves making an HTTP request to the website they want to access.
Extract and parse the website’s code
Once the website grants permission to access its content, the next process of web scraping is extracting and parsing the website code. The code allows the web scraper to determine the website structure. It will then parse the code and break it down into smaller parts to identify and retrieve elements and objects predefined in the web-scraping code. The elements may include tags, classes, IDs, ratings, text, or other information you want to collect.
Save data in a preferred format
The last step is saving the data locally. The data extracted is predefined by the instructions used to build the web scraper. Subsequently, the extracted data is often stored in a structured method, such as CSV or XLS format.
Introduction to Python for Web Scraping
Python is one of the most popular programming languages, with various applications. It is a high-level programming language with straightforward syntax. This language boasts a vast ecosystem of libraries and packages that can optimize your activities across various industries.
Here are some of the reasons why you should use Python for web scraping:
It is easy to use
Python is often considered to be a simple programming language. It is less messy and complicated to use and understand. This could be because the language does not require brackets and semicolons. Therefore, Python’s readability and simplicity make it an ideal choice for building a web scraper.
In addition, the syntax is easy to understand because reading Python codes is similar to reading a regular sentence in English.
It does not require bulky codes
Another benefit of writing Python web scraping codes is that you get more with less. With a simple code, you can implement the complex process of accessing and retrieving data from web pages.
Libraries
Several libraries make Python web scraping easier and more efficient. Therefore, developers have various options and resources to customize codes in learning how to build a web scraper. These libraries also support various web scraping methods, including XPath expression and CSS selectors.
Dynamic coding
Another unique feature of the Python language is it saves time. You don’t have to spend several hours writing long codes or defining data types for variables. Instead, you can directly use the variable within the code wherever it is needed.
Active Community
Python has a large, dynamic, and active community. You can join any of the forums on the various social media platforms. So, when you are stuck or need clarification about a concept, all you need to do is ask. You will receive opinions from those who are experts or have once been in that situation.
Versatility
Python is a very versatile language because it has several applications. Since it is often used in artificial intelligence, data science, and machine learning, Python is an ideal choice for web data scraping involving processing and analysis.
In addition, Python can be used across various platforms including Windows, MacOS, or Linux. Therefore, this makes it an excellent choice regarding learning how to build a web scraper.
Prerequisites to Learning How to Build a Web Scraper
Before we dive into how to build a web scraper, let us examine some prerequisites that you need to understand.
HTML structure
HTML tags
You may be unfamiliar with HTML structures if you are not tech-savvy. One way to find HTML tags is to use developer tools. Browsers like Chrome, Firefox, and Internet Explorer have developer tools that display the HTML elements of a web page. For example, if you are using Chrome, when you click on three vertical dots in the upper right corner of the browser, then click on More Tools and select Developers Tools. This will display the HTML structure of the website.
Usually, all the elements in the HTML can be found within the opening and closing body tags. Subsequently, every element has its opening and closing tags. When an element is nested in an HTML structure, it is an indication that the element is a child element of the parent element.
Therefore, in learning how to build a Python web scraper, you need to identify the elements you want to scrap based on the tag name and whether it is a child or parent element.
HTML elements
The efficiency of a Python web scraper depends on how you write the code. Therefore, it becomes a priority to understand HTML elements. In simpler terms, if you don’t instruct the web scraper on the right HTML element to interact with, you may be left with irrelevant or too much data.
For example, you can write a Python script to extract the <h1> element. This will produce the intended result if there is only one <h1> element on the page. However, if they are more than one, the Python code has to specify which of the <h1> elements- first, second, last, or all.
In addition, most elements come with “class” and “id” attributes, which allows you to make your Python web scraper code more specific. Therefore, including the HTML elements, class, and ID plays a significant role in ensuring the Python web scrapers get the actual data you need.
Python Basics for building a web scraper 
Install Python and supporting software
Since you are learning how to build a web scraper with Python, you need to download and install the language. One of the reasons many people choose Python as the best programming language is because its syntax is simple and easy to understand. Subsequently, once you have gone through the basis, you can have your Python web scraper in a few minutes. Be sure to download the latest version (they often come with upgraded features) from Python’s official website.
Install an IDE or code editor
Choosing between a code editor and an Integrated Development Environment (IDE) depends on your experience, preference, and project requirements. As a beginner working on Python projects, you may use the IDE. It is easier to use, provides all the required tools, and you don’t need to configure your development environment. PyCharm is a popular example of a full-fledged IDE.
The function of the code editor is to create, modify, and save program files. In addition, the code editor can identify and highlight any errors in your code. As a result, it optimizes your productivity and makes the process of writing codes for Python web scraping more efficient. The code editor is a preferred option for expert programmers. Examples include VSCode and Sublime Text 2.
Create a Python web scraping folder
Now that we have downloaded them, you must create a new Python project folder. Although some people leave their downloads on the desktop or download folder, creating a designated folder helps to organize your files. Inside the new folder you created, create a file, which you may name webscraper.py. In addition, you may need to create another file.
Python Virtual Environment
The next thing you need to handle is the virtual environment. Using a virtual environment provides an isolated space for each project to avoid interference. For example, you need to work with different versions of libraries for different projects. The virtual environment prevents dependency conflicts between the projects. In addition, the changes you make to a project will not affect any other project on your computer.
The venv tool can be used to create a virtual environment. You need to install the package on your computer. Subsequently, to create a new virtual environment, use this command: python -m venv newenv. After creating the environment, you need to activate it before you can use it to build a Python web scraper.
For Windows, you can activate it with: newenv\Scripts\activate
For MacOS and Linux: source myenv/bin/activate
Therefore, activating a virtual environment changes the Python environment such that only the libraries installed are used to create your Python script. In addition, using virtual environments is highly recommended for Python projects to manage dependencies effectively.
Install Python web scraping libraries
Python web scraping libraries are central in learning how to build a web scraper. One of the advantages of using Python for web scraping is the vast selection of libraries. Since there are several Python web scraping libraries, you need to study them to understand the best option for you.
Although there are various types of python web scraping libraries, let us look at some of them:
-
Requests library
The request library sends HTTP requests to the website you intend to extract their data. Once the package is running, the HTTP request returns a response object with all the response data.
Getting data from the web begins with HTTP requests like Post or Get to the website, which returns a response containing the data. One of the challenges of using Python HTTP libraries is they often require bulky lines of code. However, the request library simplifies this problem by using less bulky codes, which are easier to understand and implement. Run the pip install request command to install the request package on your device.
In addition, it is easy to integrate proxy servers with request packages. Regardless of the benefit of simplicity that comes with the request package, it has a limitation. This library does not parse the extracted HTML data. In simpler terms, it cannot convert data scraped from the internet into a readable form ready for analysis.
-
BeautifulSoup
BeautifulSoup is a powerful Python library that plays a significant role in web data scraping. Run the command pip install beautifulsoup4 to install the package on your device. Beautiful Soup provides simplified solutions for navigating and modifying a DOM tree.
In addition, BeautifulSoup is an excellent choice that parses XML and HTML documents. Moreover, it can convert an invalid markup into a parse tree. Therefore, it offers you the flexibility of implementing various parsing strategies. Alternatively, this package allows you to trade speed for flexibility. If you need to parse any data on the web, BeautifulSoup will do an excellent job.
BeautifulSoup is limited because its unique function is parsing data. Therefore, it cannot be used to request data from the internet. As a result, it is often used together with the Python Request Package.
BeautifulSoup can detect page encoding, which further optimizes the authenticity of data extracted from the HTML file. In addition, you can customize BeautifulSoup with a few lines of code to identify and extract specific data.
- MechanicalSoup
MechanicalSoup is a Python web scraping tool built on two powerful libraries-BeautifulSoup and Request library. Therefore, MechanicalSoup boasts similar functionalities to its two mother packages. This Python web scraping tool can automate website interaction including submitting forms, following redirects, following links, and automatically sending cookies.
Since MechanicalSoup is built on BeautifulSoup, it allows you to navigate the tags of a web page. Additionally, it leverages BeautifulSoup’s methods- find all() and find() to retrieve data from an HTML document.
This library has a feature described as “StatefulBrowser,” which extends the browser and provides relevant options for interacting with HTML data as well as storing the state of the browser.
MechanicalSoup supports CSS and XPath selectors. Therefore, it is ideal for locating and interacting with elements on a website. This library offers excellent speed. It is also efficient in parsing simple web pages.
MechanicalSoup is limited to HTML pages as it does not support JavaScript. Therefore, you cannot employ this package to access and extract data on Javascript-based websites. As a result, if the website you want to interact with does not include any HTML page, MechanicalSoup may not be the best option.
-
Selenium
Remember, we mentioned that some websites were developed using JavaScript, which poses a problem for Python packages like the Request library. Some developers choose to use JavaScript because it allows them to create some unique functionality on the web page. Therefore, Selenium becomes a unique solution when you need to scrape data from these websites.
Selenium is an open-source browser automation tool that automates various processes, such as logging onto a website. It is often used to execute test scripts on web apps. One of its unique features is the ability to initiate web page rendering.
To use Selenium for data extraction, you need three things. The first is the selenium library, which you can install with the pip command: pip install selenium. Another requirement is supported web browsers like Firefox, Chrome, Safari, and Edge. Lastly, you would need drivers for the browser.
Another excellent feature of Selenium is that it interacts with data being displayed and makes it available for parsing with in-built methods or Beautiful Soup. Some developers love to use the Selenium library because it can imitate human behavior.
However, this Python library is limited in terms of the speed of data extraction. The speed reduction occurs because the package must first execute the JavaScript code for each page before preparing them for parsing. Therefore, there are better choices than Selenium for extracting large-scale data from various web pages.
How to Build a Web Scraper with Python
Now that we have all the necessary tools, we can proceed to examine a step-by-step guide on how to build a web scraper in Python.
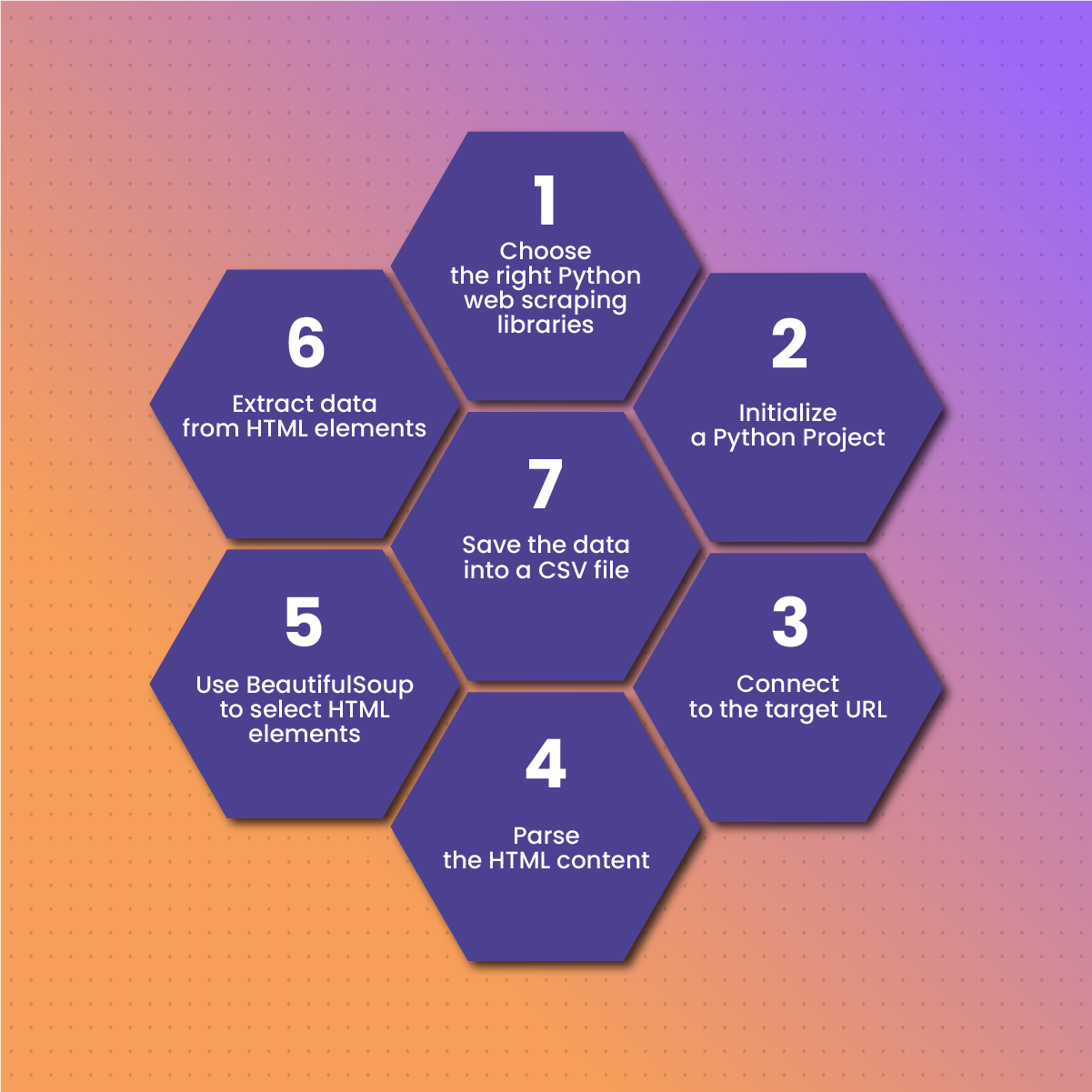
Step 1: Choose the right Python web scraping libraries
The first step in building a web scraper with Python is to choose the right libraries. There are various Python web scraping libraries with their strengths and limitations. Therefore, you need to determine the purpose of the web scraping and the libraries with the best features for it. Subsequently, you need to visit the target website in your browser. Right-click on anywhere on the website and select inspect to view the DevTools.
The target website can either be static or dynamic. If the website was written in JavaScript, it means you have to dynamically retrieve data. Subsequently, you may need to install and import Selenium into the process of building a web scraper. However, if the website is static, you do not require Selenium. Instead, using Requests and BeautifulSoup libraries is sufficient to build the Python web scraper.
Step 2: Initialize a Python Project
Once you have chosen your preferred Python web scraping tool, the next step is to initialize a Python project- you need a single .py file.
You need to use an advanced IDE to optimize the process of building a web scraper. The most common option for setting up a Python project is PyCharm.
Initialize a Python project by opening PyCharm, selecting “File > New Project,” then in the popup window, select “Pure Python,” and create a new project.
Once you click Create, you have access to the blank Python project. By default, PyCharm will initialize a main.py file, but you can rename it.
Import the Python libraries you want to use to build a web scraper at the top of the script. However, you may need to uninstall and reinstall them if the libraries are in red.
Step 3: Connect to the target URL
The next step in building a web scraper is to connect to the target URL. Subsequently, you need to copy the entire URL of the target website from your browser into your Python script. Do not exclude the HTTP or HTTPS section to avoid getting an error response. The request library sends the request to download the page with this code:
page = requests.get(‘https://www.examples.com’)
The Request library uses the get() or post() functions to make a request to the target website. It then returns a response object containing the server response.
If the request is successful, you will receive the HTTP 200 OK status response code. On the other hand, a 4xx or 5xx HTTP status code means the request was unsuccessful. Several factors could contribute to the failed request, but the most common is sending requests without a valid User-Agent.
Step 4: Parse the HTML content
BeautifulSoup Python web scraping library is crucial for parsing the HTML content. The code looks like this: soup = BeautifulSoup(page.text, ‘html.parser’). This soup variable contains a BeautifulSoup object. Subsequently, this is a tree structure generated from parsing the HTML document in the page.text with the built-in html.parser feature
Step 5: Use BeautifulSoup to select HTML elements
BeautifulSoup library has several features to select elements from the DOM when used to build a web scraper. It begins with the following functions:
- Find (): This function returns the first HTML elements that match the input selector if specified.
- Find_(): This function returns a list of HTML elements that match the selector condition passed as a parameter.
Subsequently, BeautifulSoup will look for elements on the target site based on the parameters fed to the two methods above. In addition, regarding how to build a web scraper, you can select HTML elements by:
- Tags
- ID
- Text
- Attribute
- Class
Alternatively, BeautifulSoup has the select() method that allows you to apply a CSS selector directly in building a web scraper. Subsequently, you can use the following CSS selectors on .quote:
- .text
- .author
- .tags
Step 6: Extract data from HTML elements
The next step is to extract data from the HTML elements. Subsequently, you need to initialize an array variable via quotes = [ ]. Use soup to extract the quote elements from the DOM by applying the .quote CSS.
The Beautiful Soup find() method will retrieve the single HTML element of interest. Since there is more than one tag string associated with the quote, you should store them in a list. In addition, the find_all() method will return the list of all HTML elements identified by the quote class.
Step 7: Save the data into a CSV file
You need to determine where the extracted data will be stored on your device. The web scraper iterates every page and stores the data in a readable format like CSV.
CSV is part of the Python Standard Library, so you can import and use it without the need to install additional dependencies. You simply have to create a CSV file with open( ) and populate it with the writerow() function from the Writer object of the CSV library. Subsequently, this will write each quote dictionary as a CSV-formatted row.
At this stage, you have successfully built a web scraper to extract the raw data from the target website and store them in a CSV file.
Integrating NetNut with Python Regarding How To Build a Web Scraper
Python is an excellent web scraping tool for several reasons. It has a simple syntax and several libraries that optimize the process of how to build a web scraper. Regardless of the language, the web scraper will face some challenges. Some of them include IP blocks, anti-bot, and anti-scraping measures, which have been adopted by many websites.
Therefore, it becomes useful to integrate proxies into your Python web scraper. Although there are several proxies, the reliability of the provider can determine the efficiency of the web scraper.
NetNut has an extensive network of over 52 million rotating residential proxies in 195 countries and over 250k mobile IPS in over 100 countries. In addition, we offer various proxy solutions to help you overcome the difficulties associated with Python web scraper. When you scrape a website, your IP address is exposed. As a result, the website may ban your IP address if your activities are aggressive and frequent. However, with NetNut proxies, you can avoid IP bans and continue to access the data you need.
NetNut proxies allow you to scrape websites from all over the globe. Some websites have location bans, which becomes a challenge for tasks like geo-targeted scraping. However, with rotating proxies, you can bypass these geographical restrictions and extract data from websites.
Alternatively, you can use our in-house tool- NetNut Scraper API, to collect data from any website. This method is useful if you don’t want to build a Python web scraper from scratch. Moreover, the API organizes your data so that it is easy to analyze and interpret.
Furthermore, if you want to scrape data using your mobile device, NetNut also has a customized solution for you. NetNut’s Mobile Proxy uses real phone IPs for efficient web scraping and auto-rotates IPs for continuous data collection.
Conclusion
This guide has examined how to build a web scraper with Python. A web scraper is a tool that allows users to access websites and collect data. The data can be used for several purposes, including SEO monitoring, competitor analysis, social media analysis, and academic research.
Python is a programming language that comes with several web scraping libraries. In addition, it has a simple syntax, and it is easy to read. Subsequently, this guide has examined the prerequisites, software, and steps required to build a web scraper with Python.
However, some websites employ several anti-scraping measures, including dynamic contents, IP blocks, and CAPTCHAs. Therefore, you need a reliable proxy server to overcome these challenges.
Contact us today to get the industry-leading features for your web scraping needs!
Frequently Asked Questions
What is a Web Scraper?
A web scraper is a tool that can extract data from websites quickly and effectively. Subsequently, a Python web scraper uses the Python programming language to automate the process of web data retrieval.
It can also be described as a bot or program that navigates websites, accesses web pages, extracts data from them, and stores them in a database or local folder. In addition, the efficiency of a Python web scraper lies in its ability to automate repetitive tasks while ensuring accuracy.
Is Python a good language for building a web scraper?
Yes, Python is an excellent language for building a web scraper. It has several features that make it a top choice for web scraping activities. First, Python is easy to learn and use, which makes it beginner-friendly. In addition, Python has several web scraping libraries like BeautifulSoup, which makes building a scraper efficient.
What are the applications of Python web scraper?
Python web scrapers have various applications, including:
- Monitoring competitor prices to maintain competitive pricing
- Gathering market data to identify trends and patterns
- Collecting real estate listings to understand the market dynamics
- Analysis of news content from various online sources
- Social media data extraction to understand public sentiments
- Academic research to collect data from multiple academic sources effectively
- Optimizing SEO analysis to improve search engine rankings





