Introduction
Seeing how the world has evolved from relying on manual copying and pasting to using AI and programming languages for web data extraction is a marvel. This technological leap was required to address the challenges associated with traditional web data extraction.
The need for data became more prominent as companies began to harness its powers in optimizing operations. Access to past and current data can guide predictions about decision-making. As a result, AI web scraping Python became necessary to extract, parse, and store data while resolving the challenges of traditional data collection.
What is AI Web Scraping Python?
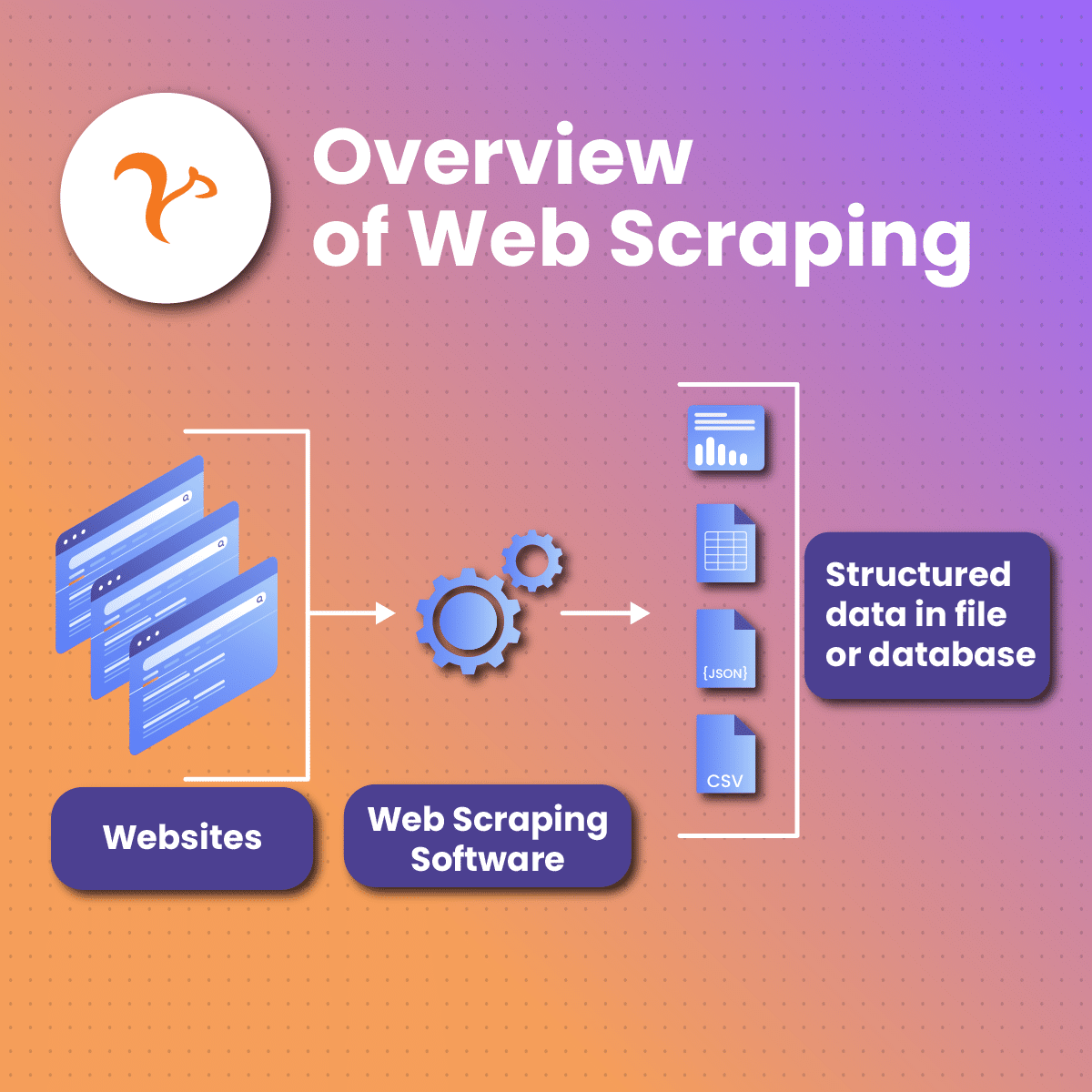
AI web scraping Python involves using artificial intelligence algorithms and Python – a programming language to automate the web scraping process. Subsequently, AI web scraping Python becomes necessary when scraping data from dynamic websites. In addition, you can use it when extracting data from websites that utilize anti-bot measures.
Furthermore, AI web scraping Python can become beneficial if you need to categorize or analyze extracted data.
Advantages of AI Web Scraping Python
Python remains a top choice among the best programming languages for web scraping. Here are some of the benefits of AI web scraping Python:
Ease of use
One of the top reasons to adopt AI web scraping Python is its ease of use. Coding AI web scraping Python is simple. This is because the codes do not require semicolons or curly braces, as seen with other popular programming languages. Subsequently, AI web scraping Python code is less messy and easy to use.
Libraries
AI web scraping Python stands out for its diverse libraries, including request, BeautifulSoup, mechanical soup, and others. These libraries offer diverse tools for handling different tasks. Therefore, AI web scraping Python libraries are ideal for data collection and further data manipulation.
Easy to understand
Another advantage of using AI web scraping Python is its simplicity. Python has an easily understandable syntax. Since AI web scraping Python code is similar to English, it is very expressive and easy to read. In addition, the indentation used in AI web scraping Python is beneficial to differentiate between scopes in the code.
Active community
Python is among the top three most popular programming languages in the world. As a result, it has a big and active community. Subsequently, suppose you run into any problems with AI web scraping Python code. In that case, you can always seek help from the community.
It does not require bulky codes
Another advantage of AI web scraping Python is that it does not require bulky codes. Subsequently, you can achieve a large task like web scraping with small code. In addition, this feature allows you to save time as you don’t need to write several pages of code to execute a complex task.
Dynamic coding
AI web scraping Python is often preferred because you can dynamically type the codes. In simpler terms, you don’t have to define data types for variables. Instead, you can use these variables directly wherever necessary in the AI web scraping Python code. As a result, writing the code is more efficient and faster.
How Does AI Web Scraping Python Work?
AI web scraping Python is an exciting journey, and many organizations leverage it for several uses. As discussed earlier, AI web scraping Python code is easy to write, and there are multiple libraries to work with. Here is how to get started with AI web scraping Python:
Install Python
Installing the programming language is the first step in AI web scraping Python. Go to the official website and download the latest Python version compatible with your operating system.
In addition, to work with AI web scraping Python, you may also need to download a code editor. It is useful in creating, modifying, and saving files. Moreover, the code editor can identify errors in the AI web scraping Python code.
Install Libraries
You cannot work with AI web scraping Python without the libraries. There are multiple libraries with different functions. You may need the Request, BeautifulSoup, and Scrapy libraries. In addition, you can use the pip package manager to install these libraries to work with AI web scraping Python.
Python request library is a popular package that allows you to send and receive HTTP requests. It is often used with other libraries to maximize AI web scraping Python activities. In addition, you can use this Python web scraping package to download the HTML codes from the website you want to scrape data from.
In addition, the requests get ( ) function is used to send an HTTP GET request to the target page URL and get ( ) response with the Python representation containing the HTML document. BeautifulSoup is also commonly used because it makes parsing XML and HTML documents easy.
Identify target website
After downloading all the required software, it gets a bit less complicated. To work with AI web scraping Python, first identify the website you want to extract data from. Subsequently, you must inspect the page to identify the HTML tags, classes, and IDs. These elements can help you tailor the AI web scraping Python code to find specific information on the web page.
In addition, before you go on with AI web scraping Python, get familiar with the terms and conditions as well as the website’s robot.txt file.
Test the AI web scraping Python script
Before you go too far with the AI web scraping Python activity, create a folder that holds all the packages and the script. Once you finish the AI web scraping Python script, you need to test it before attempting a large-scale web data collection.
Open your terminal and run the command (after adding the website URL) to test the AI web scraping Python script.
Collect and save the data
To extract data using AI web scraping Python, you need to parse the HTML content with BeautifulSoup. This library is equipped with tools for creating and modifying parsed trees such that it is easy to understand the HTML elements of a website.
Furthermore, the data extracted with AI web scraping Python can be stored in CSV, XLM, or JSON format.
NetNut: Integrating AI Web Scraping Python with Proxy Servers
Some challenges associated with AI web scraping Python are anonymity and geo-locked content. However, NetNut offers various proxy solutions to help you avoid IP bans and enjoy unlimited access to data.
In addition, NetNut proxies allow you to scrape websites from all over the globe. Regardless of a website’s location bans, you can bypass these geographical restrictions and extract data with proxies.
Alternatively, you can use our in-house solution- NetNut Scraper API. This method helps you extract data from various websites while eliminating the need for codes and libraries. In addition, Netnut Scraping API organizes your data to make it easy to analyze and interpret.
Have you ever needed to scrape data using your mobile device? NetNut offers a customized solution- Mobile Proxy, which uses real phone IPs and IP rotation for data collection.
Conclusion
In this article, we have examined AI web scraping Python. AI web scraping Python involves the use of artificial intelligence algorithms and Python for the extraction of data. Some of the benefits of using Python are its ease of use, simple syntax, active community, and rich libraries.
Using AI web scraping Python begins with installing Python, libraries, and other software. Identify the target website you want to scrape data from and inspect it. Remember to test the script before launching it. Bear in mind that aggressive scrapping can significantly reduce the website processing speed. As a result, your IP address can be blacklisted or banned.
NetNut proxies allow you to hide your IP address, which makes IP bans almost impossible. In addition, it allows you to bypass geographical restrictions.
Kindly contact us if you need to speak to an expert on the best proxy solution for your web scraping needs.
Frequently Asked Questions
What are some ethical AI web scraping Python practices?
Ethical web scraping helps you avoid legal and ethical problems associated with web scraping. In addition, it makes your AI web scraping Python activities effective. They include:
- Scrape respectfully to avoid disrupting the normal operations on the website
- Utilize throttling and delay mechanisms in your AI web scraping Python code to avoid overloading a website with requests
- Use a unique user agent to help you pass as a regular user instead of a bot
- Clean, sort, and validate data collected to ensure it is reliable and consistent
What technologies and techniques are associated with AI web scraping Python?
AI web scraping Python is an approach that uses unique technologies and techniques to adapt to dynamic websites and extract data. These approaches include:
- Natural language processing: This technology is useful in AI web scraping Python to derive insights from collected data. NLP can be used for entity recognition, content summarization, sentiment analysis, and more.
- Adaptive scraping: AI web scraping Python uses adaptive scraping technology, which combines AI and machine learning. As a result, the scrapers can make dynamic adjustments based on the website’s structure.
- Imitating human browsing patterns: Another technique to AI web scraping Python is the generation of human-like browsing patterns. This becomes crucial since many websites employ anti-scraping measures, often detecting bot behavior.
- Generative AI models: Generative AI applies to AI web scraping Python to optimize its adaptability to data collection.
Is AI web scraping Python legal?
Yes, because web scraping is not outlawed. However, it becomes necessary to practice ethical AI web scraping Python. Some websites have rules governing data extraction, so ensure you read them carefully before scraping. Navigate to the website’s robots.txt or terms & conditions to explore them. Although AI web scraping Python is legal, displaying the obtained data for commercial purposes may not be acceptable.