In today’s data-driven world, web scraping has become a valuable technique for extracting information from websites. However, the raw data obtained through scraping often requires further processing and refinement before it can be used for analysis or other purposes. This is where data pipelines come into play. A data pipeline is a series of processes that automate the movement and transformation of data from its source to its destination. In the context of web scraping, a data pipeline ensures that the extracted data is cleaned, transformed, and stored in a usable format. This article will guide you through the process of creating a data pipeline for scraped data, covering key concepts, tools, and best practices.
Understanding Data Pipelines
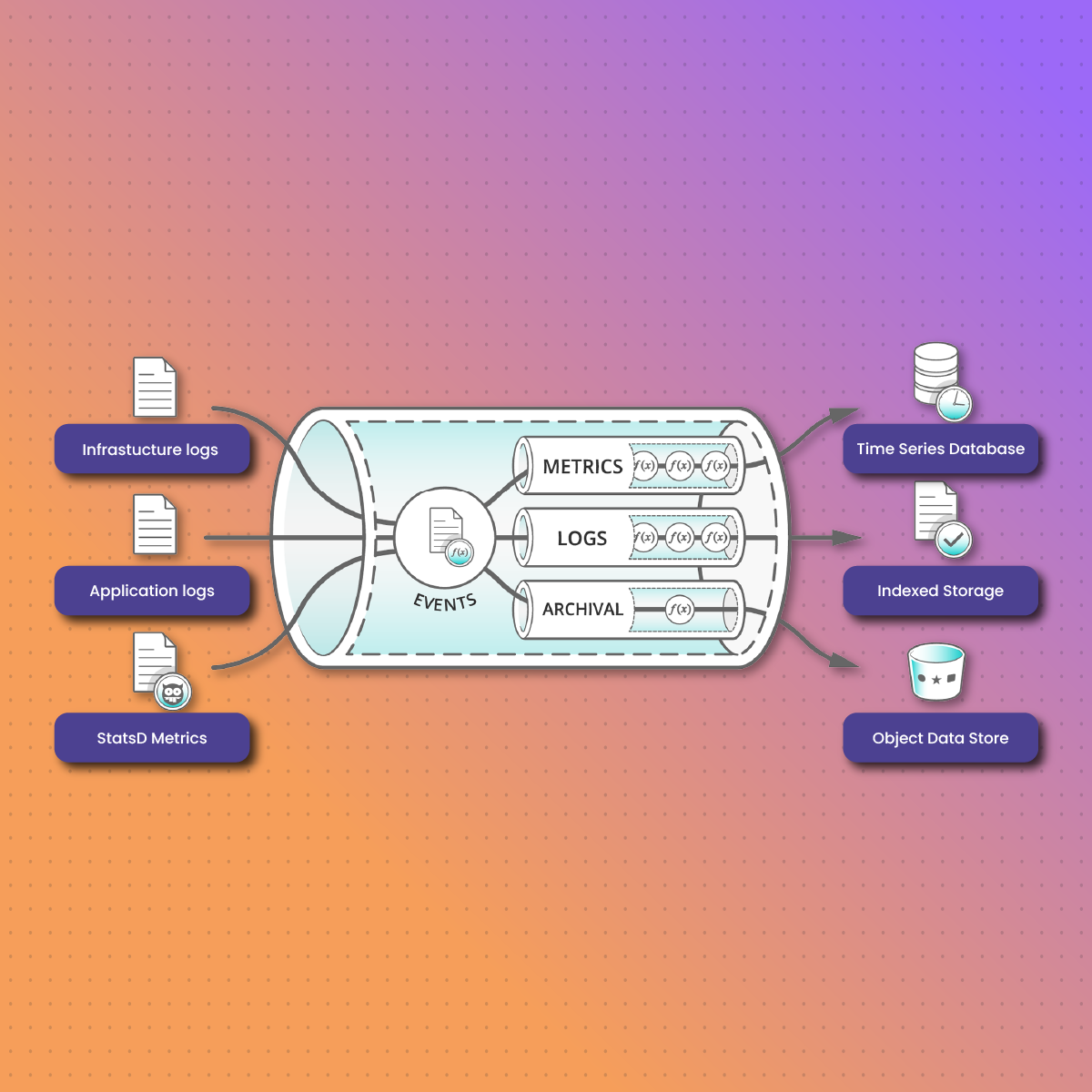
A data pipeline can be compared to a system of interconnected pipes that efficiently transports data from one location to another. It involves a set of operations designed to automatically move data from one or more sources to a target destination. Data pipelines are essential for managing and optimizing the flow of data, ensuring it’s prepared and formatted for specific uses, such as analytics, reporting, or machine learning.
Stages of a Data Pipeline
While the specific stages may vary depending on the complexity and purpose of the pipeline, a typical data pipeline for scraped data involves the following stages:
- Data Extraction: This is the first step where data is collected from various sources. In web scraping, this involves extracting data from websites using tools and techniques. For example, you might use a tool like Scrapy to crawl a website and extract specific data points.
- Data Ingestion: Once the data is extracted, it needs to be ingested or imported into the pipeline. This often involves transferring data from the source to a staging area or a processing environment. This could involve loading data from files into a database or streaming data from a message queue.
- Data Processing: In this stage, the raw data is cleaned and transformed into a usable format. This may involve removing irrelevant information, handling missing values, and converting data types. For instance, you might remove HTML tags, standardize date formats, or filter out unnecessary data.
- Data Transformation: This step involves structuring and normalizing the data for interpretation and analysis. This can include tasks like data deduplication, standardization, adding or copying data, and summarizing data. For example, you might join data from different sources, aggregate data to create summary statistics, or pivot data to change its structure.
- Data Storage: After the data is processed and transformed, it needs to be stored in a suitable location. This can be a data warehouse, a database, a cloud storage service, or any other appropriate storage medium. The choice of storage depends on factors such as data volume, data format, and access requirements.
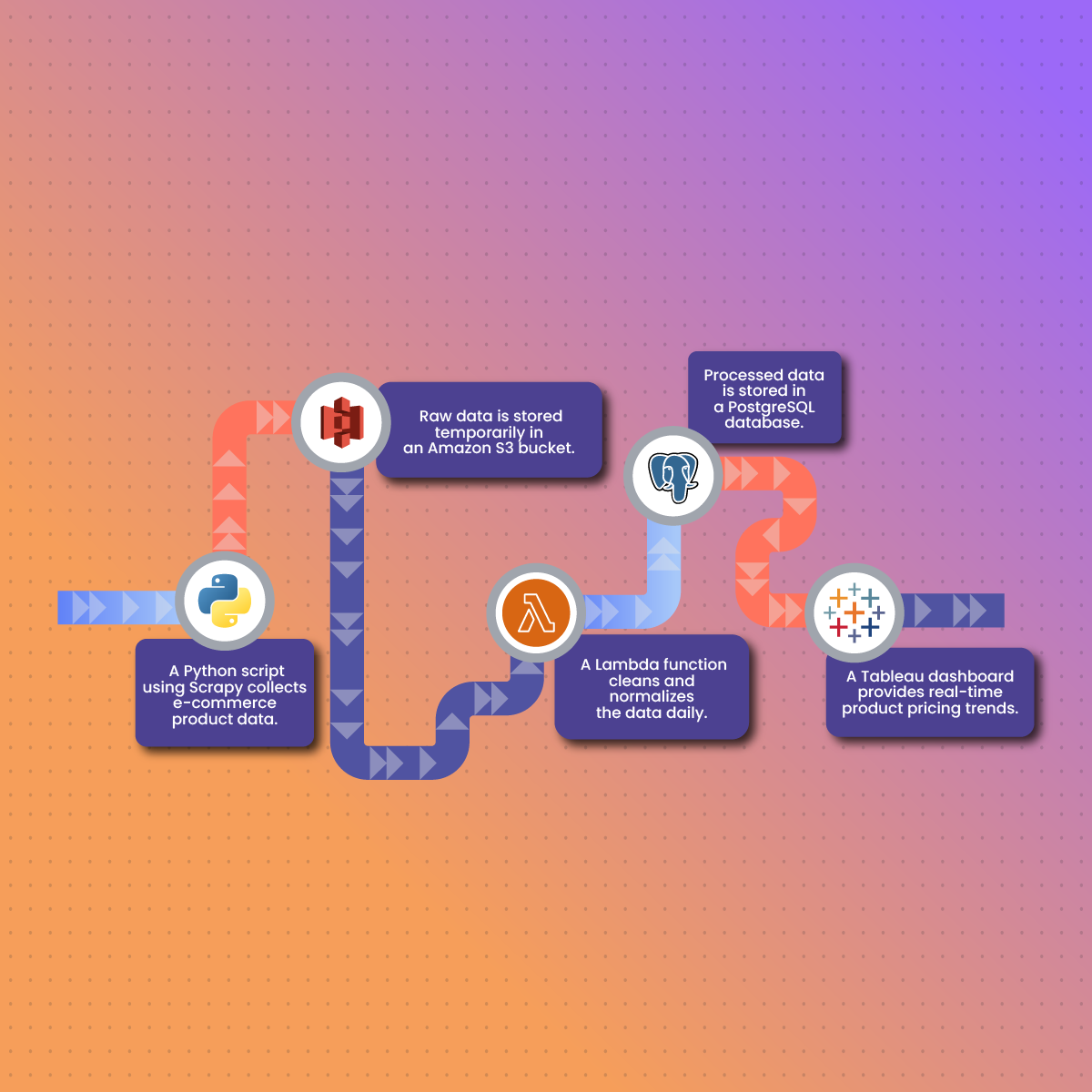
Creating a Data Pipeline for Scraped Data
Now that we have a basic understanding of data pipelines, let’s dive into the process of creating one specifically for scraped data.
1. Define Your Objectives
Before you start building your data pipeline, it’s crucial to define your objectives. What do you want to achieve with the scraped data? What kind of analysis do you plan to perform? Answering these questions will help you determine the structure and components of your pipeline.
2. Choose Your Tools
There are various tools and technologies available for building data pipelines. Some popular options include:
- Scrapy: An open-source Python framework for building web scrapers. It’s more powerful and robust than Beautiful Soup and is great for more complex scraping tasks.
- Apache Airflow: An open-source platform that lets you automate and monitor the execution of data pipelines. It helps streamline the process of building and scheduling complex workflows.
- AWS Glue: A serverless data integration service that makes data preparation simpler, faster, and cheaper. You can discover and connect to over 100 diverse data sources, manage your data in a centralized data catalog, and visually create, run, and monitor ETL pipelines to load data into your data lakes10.
- Google Cloud Dataflow: A fully managed service for executing a wide variety of data processing patterns, including batch and streaming, using the Apache Beam programming model. Dataflow can run jobs written using the Apache Beam programming model11.
The choice of tools will depend on your specific needs and preferences. Consider factors like the scale of your scraping project, the complexity of your data transformations, and your budget.
3. Design Your Pipeline
Once you have defined your objectives and chosen your tools, it’s time to design your pipeline. This involves determining the flow of data through the different stages of the pipeline. Consider the following:
- Data Sources: Identify the websites you want to scrape and the specific data you need to extract.
- Data Cleaning and Transformation: Determine the data cleaning and transformation steps required to handle missing values, inconsistencies, and formatting issues, and to prepare the data for your analysis or application.
- Data Storage: Choose a suitable storage location for the processed data.
- Scheduling and Automation: Determine how often you need to run your web scraping process and set up a schedule to automate data extraction. This ensures that your data is up-to-date and readily available for analysis. You can define specific parameters and choose the output destination for your scraped data.
4. Implement Your Pipeline
With the design in place, you can start implementing your pipeline. This involves writing code to extract, process, transform, and store the data. Use the tools you have chosen to automate these processes.
5. Test and Monitor Your Pipeline
Once your pipeline is implemented, it’s essential to test it thoroughly to ensure that it’s working as expected. Monitor the pipeline regularly to identify any errors or performance issues.
Best Practices for Data Pipelines for Scraped Data
Here are some best practices to keep in mind when designing and implementing data pipelines for scraped data:
- Design for Scalability: Design modular pipelines where components can be easily added, removed, or swapped without impacting the entire system. Using cloud-based solutions can further improve your flexibility. This will be crucial as data sources evolve.
- Incorporate Data Quality Checks: Integrate data quality checks right at the data entry point. Look for missing values, duplicates, and anomalies that might signify issues. Catching and rectifying errors at this stage saves downstream effort and prevents “garbage in, garbage out” scenarios.
- Handle Errors: Implement error handling mechanisms to gracefully handle unexpected situations, such as website changes or network issues.
- Monitor and Log: Monitor your pipeline’s performance and log relevant information for debugging and troubleshooting.
- Respect Website Terms of Service: Always adhere to the terms of service of the websites you are scraping. Avoid overloading websites with requests and use appropriate scraping techniques.
Data Cleaning and Transformation
Data cleaning and transformation are essential steps in any data pipeline, especially for scraped data, which can be messy and unstructured. Let’s explore some common techniques:
Data Cleaning Techniques
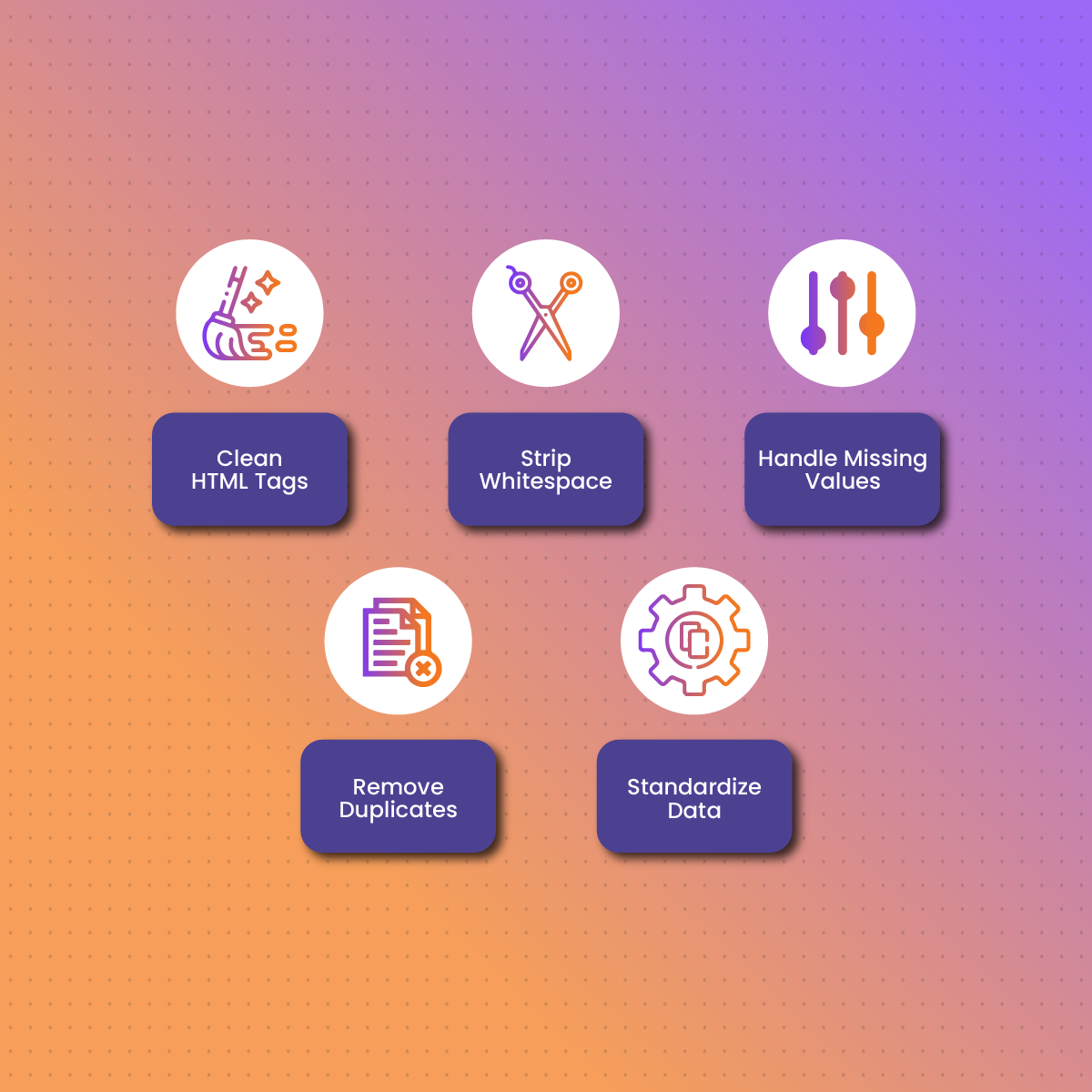
- Clean HTML Tags: Remove HTML tags from the scraped data while retaining the text content. You can use libraries like Beautiful Soup in Python to parse the HTML and extract the text. For example, if you have scraped data that includes HTML tags like <p> or <h1>, you can use Beautiful Soup’s get_text() method to extract only the text content.
- Strip Whitespace: Remove unnecessary spaces, tabs, and newline characters. This can be done using string manipulation functions in your programming language of choice.
- Handle Missing Values: Decide how to handle missing data, such as filling in missing values or removing records with missing values. You can use techniques like imputation to fill in missing values based on other data in the dataset.
- Remove Duplicates: Identify and remove duplicate records. This is important to ensure that your analysis is not skewed by duplicate data.
- Standardize Data: Ensure data consistency by standardizing formats, such as date formats and units of measurement. For example, you might convert all dates to a standard format like YYYY-MM-DD.
Data Transformation Techniques
- Aggregating Data: Combining data from multiple sources or records. This could involve calculating sums, averages, or other aggregate statistics.
- Parsing Data: Extracting specific information from the scraped data. For example, you might extract the price and product name from a product page.
- Converting Data Types: Changing data types, such as converting strings to numbers or dates. This is often necessary to perform calculations or analysis on the data.
- Enriching Data: Adding additional information to the scraped data, such as geographical locations or sentiment analysis results. This can add valuable context to your data.
Data Storage
Choosing the right storage location for your scraped data is essential. Consider the following factors:
- Data Volume: How much data do you need to store?
- Data Format: What is the format of your data (e.g., CSV, JSON, database)?
- Access Requirements: How often do you need to access the data?
- Security: How sensitive is the data?
Here’s a table summarizing some popular data storage options:
| Storage Option | Description | Suitable for |
|---|---|---|
| Cloud Storage | Services like Amazon S3, Google Cloud Storage, and Azure Blob Storage offer scalable and cost-effective storage solutions. | Storing large volumes of data, unstructured data, and data that needs to be accessed infrequently. |
| Databases | Relational databases like MySQL and PostgreSQL are suitable for structured data. NoSQL databases like MongoDB are better suited for unstructured or semi-structured data. | Storing structured data, data that needs to be queried frequently, and data with complex relationships. |
| Data Warehouses | Data warehouses like Amazon Redshift, Google BigQuery, and Snowflake are designed for analytical processing and can handle large volumes of data. | Storing large volumes of data for analytical processing, data from multiple sources, and data that needs to be accessed quickly for analysis. |
Conclusion
Creating a data pipeline for scraped data is essential for ensuring that the extracted data is cleaned, transformed, and stored in a usable format. By following the steps outlined in this article and adhering to best practices, you can build efficient and reliable data pipelines that support your data analysis and application needs. Choosing the right tools, designing your pipeline carefully, and implementing robust data cleaning and transformation processes are crucial for success.
Data pipelines offer several benefits for web scraping, including increased efficiency, reduced manual effort, and improved data quality. They enable you to consolidate data from various sources, enhance accessibility, and support decision-making. Moreover, data pipelines can be used to perform real-time analytics on time-sensitive data, such as fraud detection and targeted marketing campaigns.
Remember to design your pipeline for scalability, incorporate data quality checks, handle errors gracefully, monitor performance, and respect website terms of service. With a well-designed data pipeline, you can unlock the full potential of web scraping and gain valuable insights from the vast amount of data available on the internet.






