Uncover LLM data science: its meaning, core functions, and practical applications, while delving into its influence on analytics and language models.
Understanding Large Language Models (LLMs) in Data Science

Definition and background
LLM data science refers to the application of Large Language Models in the field of data science. These models, such as GPT-3, are a type of artificial intelligence trained on vast amounts of text data to generate human-like responses to natural language inputs. LLMs have transformed the way data scientists work with text data, enabling them to analyze and generate insights from unstructured data with unprecedented accuracy and efficiency.
Key terms related to LLMs
- Large Language Models (LLMs): A type of AI that generates human-like responses to natural language inputs.
- Natural Language Processing (NLP): A subfield of AI focused on enabling computers to understand, interpret, and generate human language.
- Word Embeddings: Algorithms that represent words as numerical vectors based on their meanings.
- Attention Mechanisms: Algorithms that help LLMs focus on specific parts of the input text when generating outputs.
- Transformers: A popular neural network architecture in LLM research, known for its self-attention mechanisms.
LLMs: Basic Functions and Capabilities
Natural language processing (NLP)
LLM data science leverages NLP techniques to understand and process human language. This enables data scientists to work with text data more efficiently, extracting insights and patterns that would be difficult to identify manually. NLP tasks that LLMs excel at include text classification, sentiment analysis, and named entity recognition.
Text generation and completion
One of the primary capabilities of LLMs is generating coherent and contextually appropriate text. This can be used for tasks such as generating summaries, writing articles, or completing text prompts. By providing a prompt, LLMs can generate creative and relevant responses that are often difficult to distinguish from human-generated text.
Sentiment analysis and text classification
LLMs are effective at analyzing sentiment and categorizing text data. By understanding the underlying emotions and themes in a piece of text, LLM data science can be applied to tasks such as customer feedback analysis, social media monitoring, and market research.
Major Algorithms and Techniques in LLM Data Science
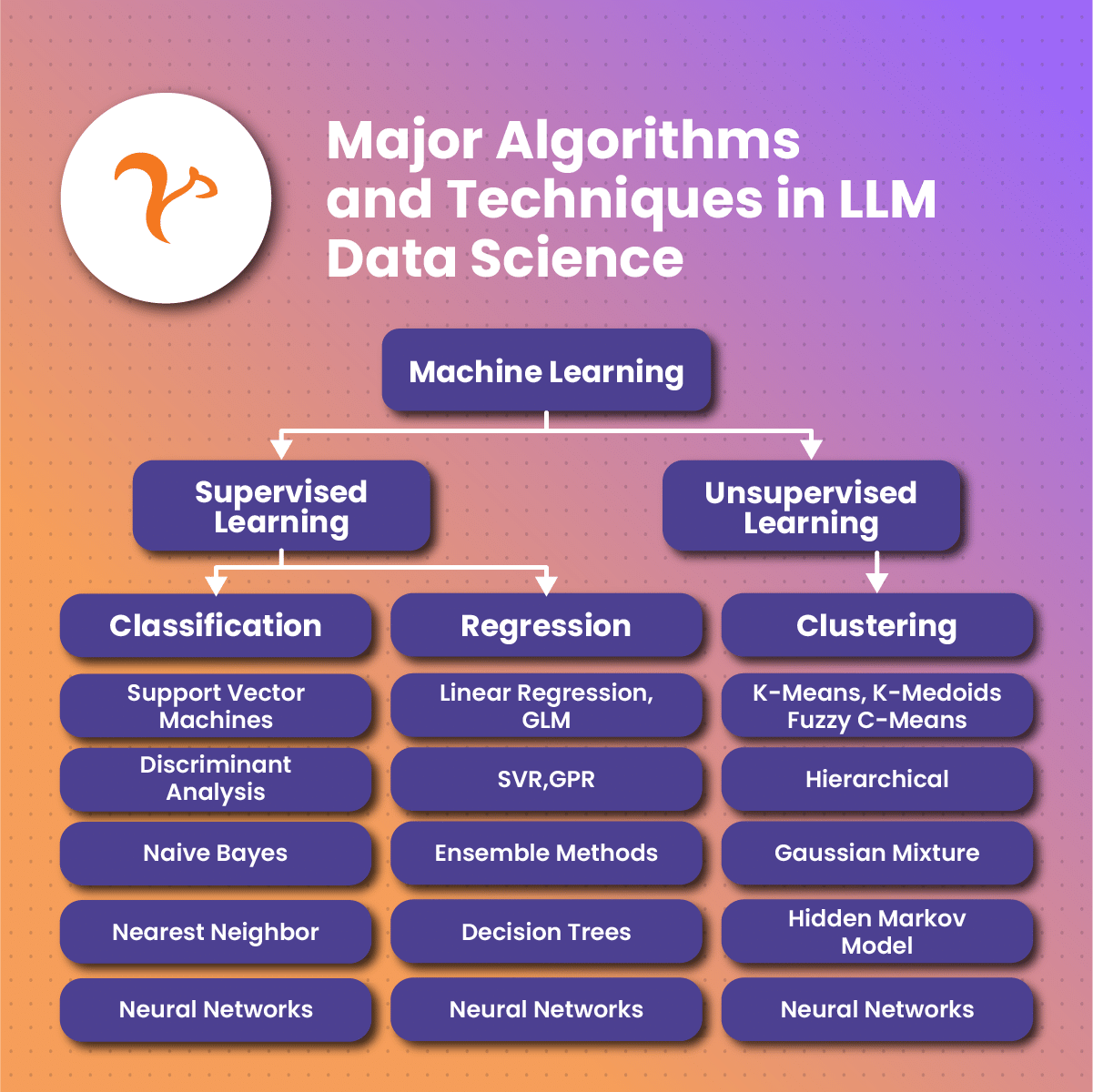
Word embeddings
Word embeddings are a crucial technique in LLM data science. They represent words as high-dimensional vectors, with similar meanings situated closer together. This numerical representation enables LLMs to process and understand text data more effectively.
Attention mechanisms
Attention mechanisms help LLMs focus on specific parts of the input text when generating outputs. This enables the models to consider the context and sentiment of the input, resulting in more accurate and coherent responses.
Transformers
Transformers are a popular neural network architecture in LLM research. They use self-attention mechanisms to process input data, allowing them to capture long-term dependencies in human language effectively. Transformers have played a crucial role in the development of state-of-the-art LLMs like GPT-3.
The Role of Fine-Tuning in LLM Data Science
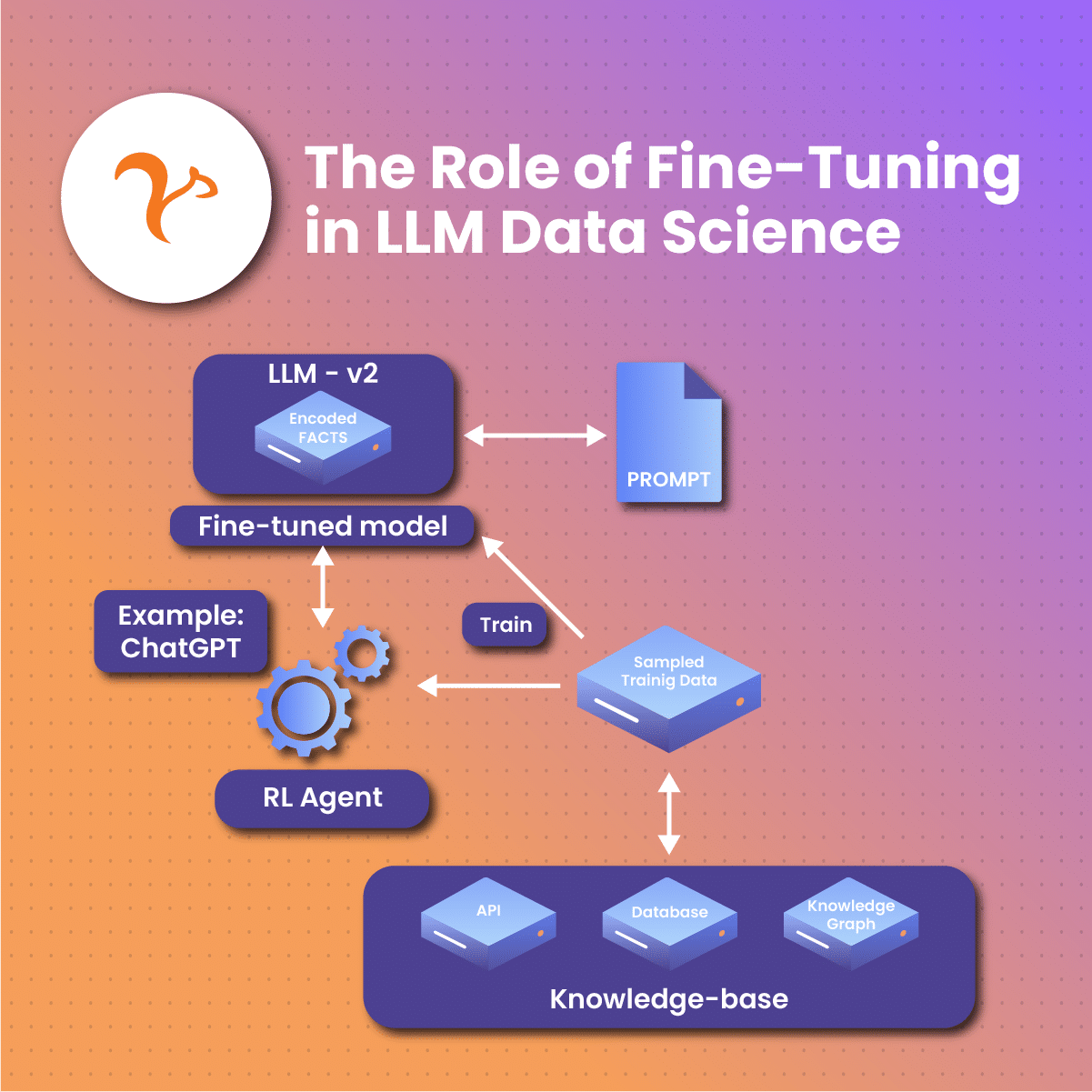
Adapting LLMs for specific tasks or domains
Fine-tuning involves training an LLM on a smaller, relevant dataset to adapt it to a specific task or domain. This process enhances the performance of LLMs for specialized tasks, such as medical diagnoses, legal advice, or financial analysis.
Benefits and challenges of fine-tuning
Fine-tuning LLMs offers several benefits, including improved performance for specific tasks and potential reduction of biases. However, fine-tuning also has its challenges, such as the need for domain expertise and the potential limitations imposed by the quality and size of the training data.
Prompt Engineering and Its Importance
The art of crafting effective prompts
Prompt engineering refers to the skillful design of inputs for LLMs to produce high-quality, coherent outputs. This is essential when working with LLMs, as the quality of the input prompt greatly affects the generated text. Prompt engineering involves providing specific topics or contexts for the AI system to generate text about or incorporate specific words or phrases into the output.
Best practices for prompt engineering
Effective prompt engineering requires a deep understanding of the capabilities and limitations of LLMs, as well as an artistic sense of crafting compelling inputs. Key aspects of prompt engineering include providing sufficient context for the LLM to generate coherent text and making slight adjustments to the input to guide the model’s response.
The Future of prompt engineering in LLM data science
As LLMs continue to improve, the role of prompt engineering may evolve or even diminish. Future LLMs might be better at understanding context and generating appropriate outputs without the need for meticulous prompt engineering. Nonetheless, the ability to craft effective prompts will remain a valuable skill for data scientists working with LLMs in the foreseeable future.
Crafting Effective Input Prompts
Examples and Best Practices
In the realm of LLM data science, crafting effective input prompts can greatly influence the quality and relevance of the generated outputs. Some best practices for prompt engineering include providing sufficient context, using clear and concise language, and experimenting with different prompt structures. Including keywords, phrases, or specific instructions can also help guide the model to produce the desired response.
Real-World Applications of LLM Data Science
Legal Industry
LLM data science has a wide range of applications in the legal industry, such as drafting legal documents, summarizing case law, and assisting with e-discovery. These AI models can also help lawyers research specific topics more efficiently and provide insights into legal strategies.
Healthcare and Medical Research
In healthcare and medical research, LLM data science can be utilized for tasks like extracting relevant information from medical literature, generating reports for patients, and analyzing clinical trial data. Additionally, these models can assist in predicting disease outbreaks and identifying potential treatments based on existing research.
Finance and Investment
LLM data science can be used in finance and investment to analyze financial data, generate investment insights, and detect potential fraud. These models can also help in predicting market trends and generating risk assessments for investment portfolios.
Marketing and Advertising
In marketing and advertising, LLM data science can be employed for tasks like generating ad copy, analyzing customer sentiment, and personalizing content for target audiences. Additionally, these models can help in identifying trends and predicting consumer behavior, ultimately leading to more effective marketing strategies.
Customer Service and Support
LLM data science can be leveraged to improve customer service and support through chatbots and virtual assistants, which can provide instant, accurate answers to customer queries. These AI models can also analyze customer feedback and suggest improvements for products and services.
Ethical Considerations and Limitations of LLM Data Science
Bias and Fairness
One significant ethical concern in LLM data science is the potential for bias. Since these models learn from large amounts of text data, they can inadvertently absorb and perpetuate existing biases, leading to discriminatory outputs. Addressing this issue requires rigorous examination and mitigation techniques to ensure fairness in AI-generated content.
Interpretability and Transparency
Another ethical consideration in LLM data science is the lack of interpretability and transparency. Due to the complexity of these models, it can be challenging to understand how and why they arrive at specific outputs. Developing techniques to enhance interpretability is crucial for maintaining trust and accountability in AI systems.
Environmental Impact and Resource Consumption
The environmental impact and resource consumption associated with LLM data science are also concerns. The computational power required to train and run these models can substantially contribute to energy consumption and environmental degradation. Researchers are working on developing more efficient algorithms and techniques to mitigate these concerns.
Future Trends and Developments in LLM Data Science

Advances in Algorithms and Techniques
As LLM data science continues to evolve, advances in algorithms and techniques are expected to improve the performance and efficiency of these models. New approaches, such as unsupervised and self-supervised learning, may lead to even more powerful and versatile AI systems.
Addressing Current Limitations and Challenges
Future developments in LLM data science will likely address current limitations and challenges, such as bias, interpretability, and environmental impact. Researchers and developers will work towards creating more ethical, transparent, and efficient AI models.
Emerging Applications and Use Cases
As LLM data science progresses, new applications and use cases will continue to emerge across various industries. These AI models may play an increasingly important role in areas like education, journalism, entertainment, and many other sectors, offering innovative solutions and enhancing productivity.
Top Advantages and Disadvantages of LLM Data Science
Advantages of LLM Data Science
Powerful Text Generation and Understanding
LLM data science enables powerful text generation and understanding capabilities, allowing AI models to produce human-like responses and accurately interpret the context of the input text.
Wide Range of Applications
LLMs have numerous applications across various industries, such as finance, healthcare, marketing, and customer service, offering innovative solutions and improving efficiency. Scalability and Adaptability
LLMs can be fine-tuned for specific tasks or domains, making them highly scalable and adaptable to various use cases.
Continuous Learning and Improvement
As LLMs are exposed to more data and fine-tuned for specific tasks, their performance improves over time, leading to more accurate and useful outputs.
Disadvantages of LLM Data Science
Susceptibility to Bias
LLMs can inadvertently learn biases present in their training data, leading to discriminatory outputs that reinforce existing societal inequalities.
Lack of Interpretability
Due to their complexity, LLMs are often considered “black boxes,” making it difficult to understand how and why they arrive at specific outputs. This lack of interpretability can raise concerns about trust and accountability.
Resource Intensive
LLMs require massive amounts of data and computational resources for training and running, which can be expensive to develop and maintain and contribute to environmental issues.
Comparison Table of Advantages and Disadvantages
| Advantages | Disadvantages |
| Powerful Text Generation | Susceptibility to Bias |
| Wide Range of Applications | Lack of Interpretability |
| Scalability and Adaptability | Resource Intensive |
| Continuous Learning & Improvement |
Note that this table format may not be directly compatible with your blog platform. You may need to recreate the table using your platform’s table formatting tools.
Resources
- BLOOM — BigScience Large Open-science Open-Access: This article explains that LLMs are resource-intensive in terms of hardware capacity, processing, and storage. It also explains that LLMs are generally used for generation (aka completion), summarization, embeddings (clustering and visually representing data), Classification, semantic search, and language translation.
- Can we boost the confidence scores of LLM answers with the help of knowledge graphs?: This article discusses how knowledge graphs might work best with LLMs. Some projects have used knowledge graphs to inform or augment LLMs. Others have used LLMs to generate input for knowledge graphs.
- What do large language models do in AI?: This article explains that LLMs are only as good as their training and data sources. At present, LLMs are often trained by developers who then release trained code to users. LLMs require mature and sophisticated governance. Deploying an LLM within your organization takes focus on digital ethics, the art of determining policies, and processes for managing and governing AI.
- LLMs in Science – LLMs in Scientific Research Workflows: This website offers a plethora of resources to support researchers who are eager to explore the potential of LLMs in their own work.
- Vanderbilt University Data Science Institute and Vanderbilt University …: The Data Science Institute’s AI Summer workshop is a free course designed to help researchers, educators, and students gain a deep understanding of the latest AI technologies and techniques, specifically deep learning and transformers, and how they can be used to solve a variety of problems.






