Discover Machine Learning Data Extraction techniques and tools in this practical guide and step-by-step instructions for efficient data extraction.

Understanding the importance of data extraction in machine learning
Machine Learning Data Extraction is a crucial step in the development of machine learning models. Obtaining high-quality, relevant, and accurate data is essential for training and validating models effectively. The better the data, the higher the chances of creating a robust and accurate model that can solve complex problems and make accurate predictions.
Challenges in data extraction for machine learning projects
Data extraction can be challenging due to a variety of factors such as data quality, accessibility, format, and volume. Some common challenges include:
- Incomplete or inconsistent data
- Limited access to relevant data sources
- Difficulties in combining data from different sources
- Time-consuming and labor-intensive processes
Common data formats and sources for machine learning
Data for machine learning can come in various formats, including structured (e.g., SQL databases) and unstructured data (e.g., text, images). Common sources include public datasets, web scraping, APIs, and proprietary databases.
SQL for data extraction
Connecting to databases using SQLAlchemy in Python
SQLAlchemy is a powerful library in Python that allows users to connect to a variety of databases and perform SQL queries easily. By using the create_engine function, you can establish a connection to your database and start extracting data.
Executing SQL queries and processing results
Once connected, you can execute SQL queries using the connection object, retrieve the results, and process them in a suitable format, such as a Pandas DataFrame, for further analysis and manipulation.
Web scraping for data extraction
Introduction to Beautiful Soup and Urllib Libraries
Beautiful Soup and urllib are popular Python libraries for web scraping. Beautiful Soup provides a simple way to parse HTML and XML documents, while urllib helps in opening and reading URLs.
Accessing and parsing web pages for relevant data
To scrape data from web pages, you first need to open the URL using urllib and then parse the HTML content using Beautiful Soup. This allows you to access specific elements on the page and extract relevant information.
Extracting specific information using HTML tags and attributes
Using Beautiful Soup’s find_all function, you can filter the HTML content based on specific tags and attributes, allowing you to extract the desired data points.
Handling complications and cleaning extracted data
Web scraping may involve handling complications such as missing or duplicate data, or dealing with different formats. Data cleaning techniques are necessary to ensure the extracted data is accurate and ready for use in machine learning models.

API-based data extraction
Introduction to APIs and their Role in machine learning data extraction
APIs, or Application Programming Interfaces, are web-based systems that provide access to data through specific endpoints. APIs are commonly used in Machine Learning Data Extraction to retrieve data in a structured format, such as JSON or XML.
Using the requests library in Python
The requests library is a popular choice for working with APIs in Python. It simplifies the process of sending HTTP requests and handling the returned data.
Accessing and processing data from public APIs, such as Dark Sky for weather data
By constructing the appropriate URL and using the requests library, you can access data from public APIs like Dark Sky, which provides historical and forecasted weather data. Once the data is retrieved, you can process it and convert it into a suitable format for analysis.
Normalizing JSON data and converting to data frames
For easier analysis and manipulation, you can normalize the JSON data returned by the API and convert it into a Pandas DataFrame.
Combining multiple data extraction methods for comprehensive datasets
In many machine learning projects, it is necessary to combine data from various sources and formats. By using the techniques mentioned above, you can create a comprehensive dataset that incorporates data from SQL databases, web scraping, and APIs.
Integrating data from different sources
After extracting data from various sources, you need to integrate it into a unified dataset. This may involve merging or concatenating data frames, handling missing values, and ensuring consistent data types across all sources.
Data preprocessing and feature engineering
Once you have a comprehensive dataset, you can proceed with data preprocessing and feature engineering to prepare the data for machine learning models. This may include data normalization, encoding categorical variables, and creating new features based on the extracted data.
Evaluating and refining data extraction methods
It is essential to continuously evaluate and refine your data extraction methods to ensure the quality and relevance of the data being used in your machine learning models. Regularly review your extraction processes, update them as needed, and monitor the performance of your models to maintain accuracy and effectiveness.
By following these guidelines and using the various data extraction methods discussed, you can create robust datasets for your machine-learning projects, ultimately leading to more accurate and reliable models.
Merging data from SQL, web scraping, and APIs
Combining data from multiple sources
To create a comprehensive dataset for machine learning data extraction, you may need to combine data from SQL databases, web scraping, and APIs. This process can be achieved using data manipulation libraries like Pandas in Python.
Handling inconsistencies and conflicts
When merging data from different sources, you may encounter inconsistencies or conflicts. Ensure that data types, units of measurement, and column names are consistent across all sources before merging.
Dealing with duplicates and missing values
Duplicates and missing values can lead to inaccurate machine-learning models. Use appropriate techniques to handle duplicates, such as dropping or aggregating them, and impute or remove missing values as necessary.
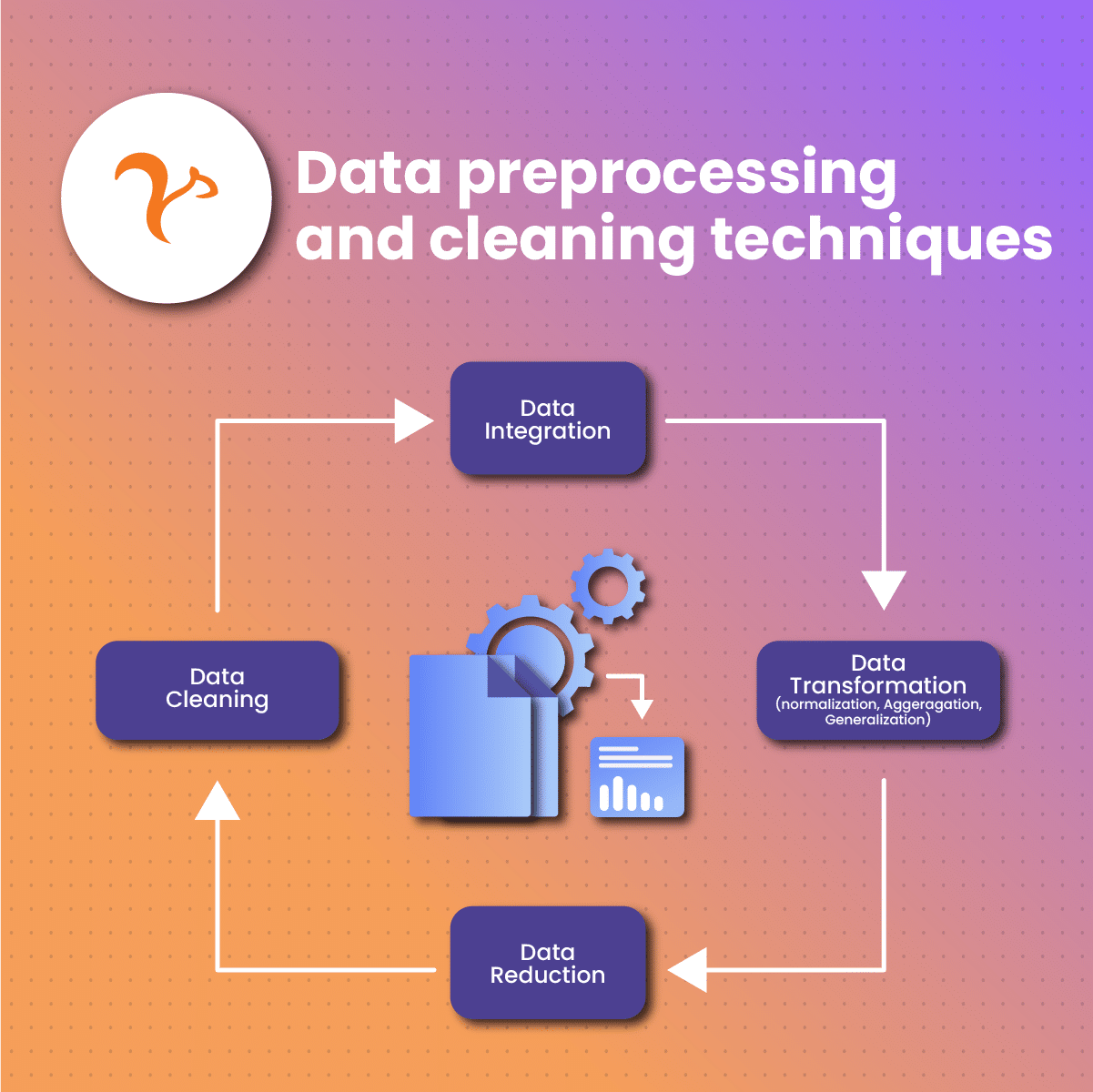
Data preprocessing and cleaning techniques
Data normalization and standardization
Normalize or standardize numerical data to ensure that features are on the same scale, which can help improve the performance of machine learning algorithms.
Encoding categorical variables
Convert categorical variables into numerical values using techniques like one-hot encoding or label encoding, making them suitable for machine learning models.
Handling outliers and noisy data
Detect and handle outliers and noisy data using techniques like clipping, winsorizing, or robust scaling to improve the quality of your dataset.
Automating data extraction processes
Building custom scripts and functions
Create custom scripts and functions to automate data extraction from SQL databases, web scraping, and APIs, allowing you to easily update and maintain your datasets.
Scheduling data extraction tasks
Use scheduling tools like cron or Python’s Schedule library to automate data extraction tasks, ensuring that your machine learning models receive the most up-to-date data.
Tips and best practices for machine learning data extraction
Choosing the right data extraction method for your project
Select the most appropriate data extraction method based on your project’s requirements, the type and format of data needed, and the availability of data sources.
Ensuring data quality and accuracy
Verify the quality and accuracy of the extracted data by performing data quality checks, validating data sources, and comparing the data against known benchmarks or trusted sources.
Handling missing or incomplete data
Address missing or incomplete data using techniques such as data imputation, data interpolation, or leveraging external data sources to fill in gaps.
Ensuring data security and privacy
Ensure that the data extraction process complies with data security and privacy regulations, including GDPR and CCPA, by anonymizing sensitive data and storing data securely.

Popular data extraction tools and libraries for machine learning
Scrapestorm
An AI-powered web scraping tool that automates the extraction of data from websites, useful for machine learning projects that require web-based data.
Altair Monarch
A powerful data preparation tool that enables users to extract and transform data from various sources, including databases, spreadsheets, and PDFs, for use in machine learning projects.
Klippa
A document processing and OCR platform that extracts and classifies data from various document types, such as invoices and receipts, useful for machine learning applications in finance and accounting.
NodeXL
An Excel add-in for network analysis and visualization that can be used to extract and analyze data from social networks, aiding machine learning projects in social media analysis and marketing.
Levity
An AI platform that allows users to train custom machine learning models to classify and extract information from documents, images, and text, suitable for various machine learning applications.
Real-world examples and case studies
Examples of successful machine learning projects using various data extraction methods
Machine learning data extraction techniques have been employed in various industries with great success. For instance, healthcare organizations have used data extraction to identify disease patterns, while e-commerce platforms have leveraged it to improve product recommendations.
Lessons learned and insights from practical implementations
- Selecting the right data extraction method is crucial for obtaining high-quality data, which is essential for accurate machine learning models.
- Continuous monitoring and updating of data sources are necessary to maintain the relevance and accuracy of machine learning models.
- Ensuring data security and privacy is paramount, especially when dealing with sensitive information.
- Combining multiple data extraction methods can lead to more comprehensive datasets and improved machine learning outcomes.
- Investing in the right tools and libraries can streamline the data extraction process and boost the efficiency of machine learning projects.
Advantages and Disadvantages of Machine Learning Data Extraction
Advantages
- Accuracy and Precision: Machine learning data extraction can help improve the accuracy and precision of data by identifying patterns and trends that may not be easily detected by humans.
- Time Efficiency: Automated data extraction techniques can significantly reduce the time it takes to collect and preprocess data, allowing data scientists to focus on more important tasks.
- Scalability: Machine learning algorithms can easily scale to handle large amounts of data, making it suitable for processing and analyzing big datasets.
- Adaptability: Machine learning models can adapt and learn from new data, ensuring that they remain relevant and accurate as data sources change over time.
- Cost Savings: Automating the data extraction process can help save costs related to manual data collection and processing.
Disadvantages
- Data Quality: Machine learning data extraction is highly dependent on the quality of the data it receives. Poor data quality can result in inaccurate or unreliable models.
- Complexity: The process of implementing machine learning data extraction can be complex, requiring a deep understanding of various techniques, tools, and programming languages.
- Security and Privacy: Ensuring the security and privacy of data during the extraction process can be challenging, especially when dealing with sensitive information.
- Maintenance: Machine learning models require ongoing maintenance, monitoring, and updates to ensure their continued relevance and accuracy.
- Resource Intensive: Machine learning data extraction can be resource-intensive, requiring significant computational power and storage capabilities.
Comparison Table
| Advantages | Disadvantages |
| Accuracy and Precision | Data Quality |
| Time Efficiency | Complexity |
| Scalability | Security and Privacy |
| Adaptability | Maintenance |
| Cost Savings | Resource Intensive |
Resources
- Automate data extraction and analysis from documents | Machine Learning: This article provides an overview of AWS Intelligent Document Processing solutions from AWS Partners that can help lower costs, increase revenue, and boost engagement.
- The Role of Feature Extraction in Machine Learning | Snowflake: This article explains how feature extraction improves the efficiency and accuracy of machine learning. It also provides four ways feature extraction enables machine learning models to better serve their intended purpose.
- Automating Data Extraction with AI: PwC 3: This article discusses how integrating cutting-edge technologies such as optical character recognition (OCR), supervised machine learning, and automated analytics that incorporate natural language processing into a seamless process will require time and technical expertise.
- Machine Learning: Feature Selection and Extraction with Examples: The article provides a comprehensive explanation of these concepts, with examples to help readers understand how they work.
- Machine Learning vs OCR: Which is Better for Data Extraction?: The article provides a detailed comparison of these two methods, explaining how they work, and what types of data they are best suited for.






