Introduction
The internet is a wide space where information is just a click away. Have you ever wondered how search engines such as Google, Bing, and Yahoo manage to find the exact information you need so quickly?
The answer lies in the magic of web crawlers. Web crawlers, also known as spiders or bots, are the unsung heroes working behind the scenes to make sure the internet runs smoothly and efficiently.
A web crawler is an automated program designed to systematically browse the internet and gather information from websites. Think of it as a digital librarian that travels from site to site, reading and indexing everything it finds. This helps search engines that compete with Google to build and update their vast databases, ensuring users get the most relevant and up-to-date search results.
They organize the web’s information, making it searchable and accessible for everyone. Without them, we would struggle to find the right answers among billions of web pages. To improve your knowledge of these bots, we will work you through how they work, the different types, their benefits, and compare them with web scraping.
How Do Web Crawlers Work?
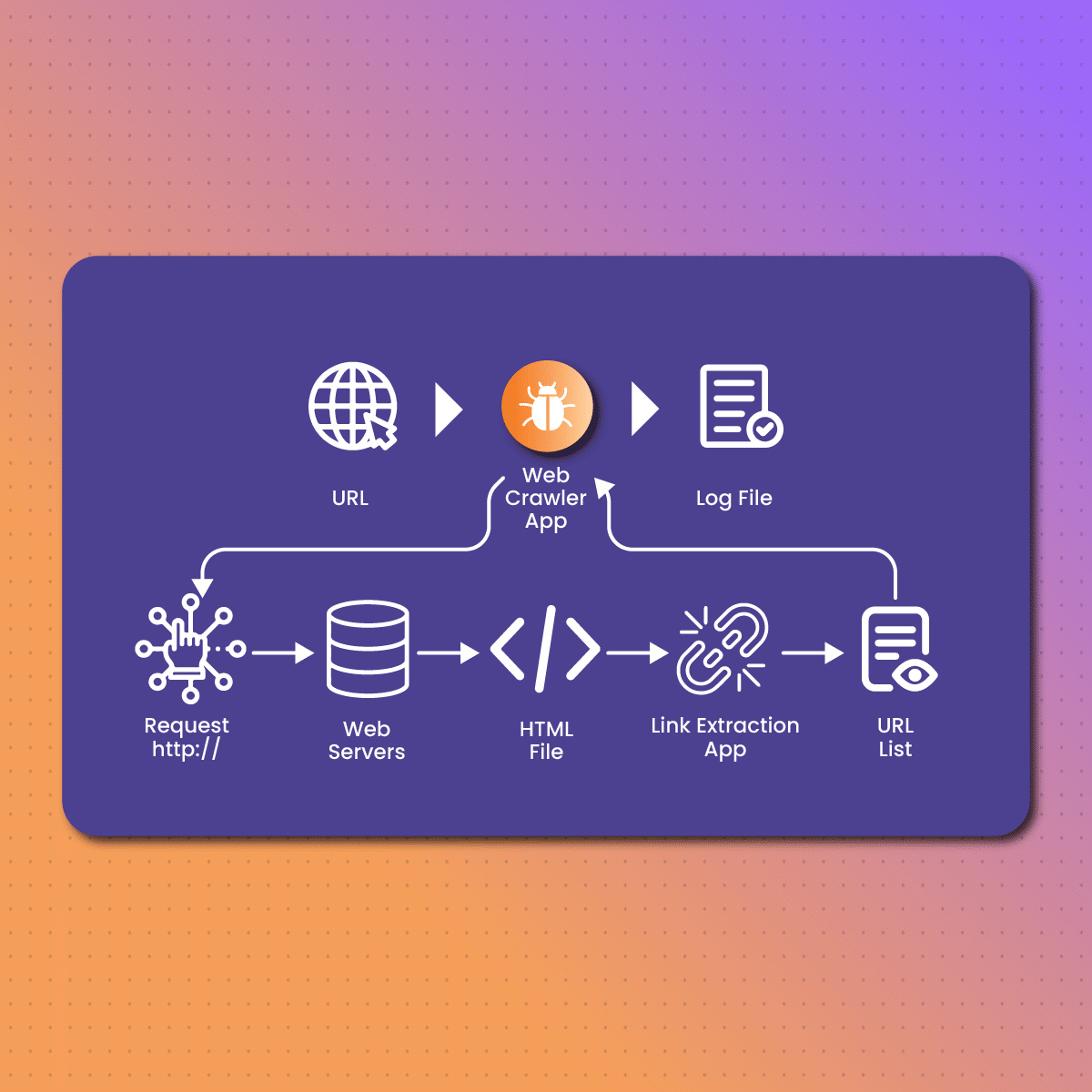
Web crawlers follow a systematic process to navigate the internet and gather valuable information. This process involves several key steps, each contributing to the crawler’s overall efficiency and effectiveness. Here is a detailed look at how web crawlers work:
Explanation of seed URLs
Web crawler begins its journey with a list of initial URLs known as seed URLs. These seed URLs act as the starting point for the crawling process. They are typically selected based on their relevance or importance, such as popular websites or frequently updated pages. By starting with these seeds, crawlers can quickly access a broad range of content and begin the process of exploring and indexing the web.
Process of visiting and downloading web pages
Once the crawler has its list of seed URLs, it begins to visit each URL one by one. This process is known as fetching. When a crawler fetches a page, it sends a request to the web server hosting that page, similar to how a user’s browser requests a web page. The server responds by sending the HTML content of the page back to the crawler. The crawler then downloads and stores this content in its database. This downloaded content includes not only the visible text but also metadata, images, and other embedded resources.
How crawlers find new pages to visit
After fetching and downloading a web page, the crawler analyzes the page to identify all the hyperlinks it contains. These links point to other web pages, which may be on the same website or different websites altogether. By extracting these links, the crawler can expand its reach and discover new pages to visit. This step is crucial for the crawler to build a comprehensive map of the web’s interconnected structure.
The real process of crawling
With the list of extracted links, the crawler adds new URLs to its queue of pages to visit. It then iterates through this queue, visiting and fetching each new page, extracting links, and adding more URLs to the queue. This iterative process allows the crawler to continuously explore new content, ensuring that it covers as much of the web as possible. As the crawler follows links from page to page, it uncovers the web’s vast and interconnected network of information.
Storing and organizing content for search engines
Once a web page is fetched and its content downloaded, the crawler’s job has not finished. The next crucial step is indexing. Indexing involves analyzing and organizing the content so that it can be easily retrieved and searched by the search engine. This process includes:
- Parsing the Content: Breaking down the page’s HTML structure to identify and categorize various elements such as headings, paragraphs, links, and images.
- Extracting Keywords: Identifying important keywords and phrases that are relevant to the page’s content.
- Storing Metadata: Storing additional information about the page, such as its URL, title, and description.
- Creating Index Entries: Creating entries in the search engine’s index, which act like pointers to the original content. These entries help the search engine quickly locate and display relevant pages when users perform searches.
The indexed content is stored in a highly organized and optimized database, allowing the search engine to retrieve relevant information efficiently. This enables users to receive accurate and timely search results when they query the search engine.
Integration With NetNut
NetNut is unarguably a top-tier proxy service provider. NetNut provides rotating residential proxies for a variety of online activities, such as web crawler, data mining, and online anonymity.
Subsequently, integrating NetNut proxies with web crawler is a game changer for information retrieval. These proxies facilitate a simple connection, allowing web crawlers to optimize the power of a wide and dependable network of residential proxies.
This integration simplifies the web crawling process, resulting in more efficient and accurate data extraction. NetNut has diverse residential and ISP proxies that help to improve reliability by lowering the likelihood of hitting blockages or limitations while crawling. This aids faster and more consistent data retrieval, shorter indexing times, and ensuring that the web crawler returns the most current and relevant search results.
What is the Difference Between Web Crawling and Web Scraping?
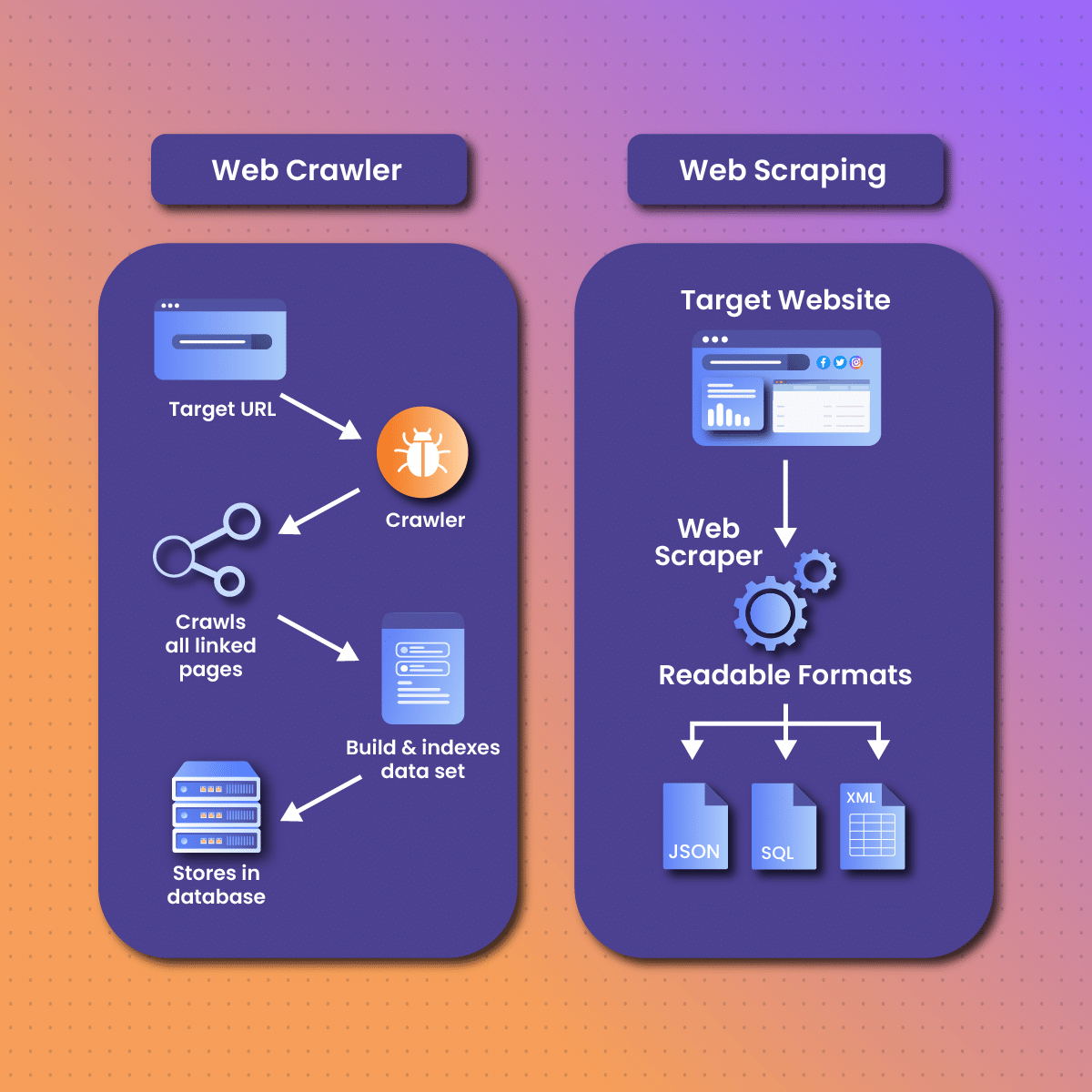
Web crawling and web scraping are two essential processes when it comes to internet data extraction. However, they serve different purposes and involve distinct work processes. Understanding the differences between the two is crucial for anyone looking to navigate the complexities of web data collection.
As earlier mentioned, the web crawling process is primarily carried out by search engine bots, such as Googlebot or Bingbot. These bots tend to build a comprehensive index of available content. Web Scraping, on the other hand, is the process of extracting specific data from web pages. This is typically done for purposes such as data analysis, market research, or competitive analysis.
Key Differences Between Web Crawler and Web Scraping
| Aspect | Web Crawling | Web Scraping | |
| Purpose | To index and discover web content | To extract specific data from web pages | |
| Scope |
|
Narrow; focuses on specific pages or data points | |
| Tools Used |
|
Custom scripts, scraping frameworks (e.g., Beautiful Soup, Scrapy) | |
| Data Structure |
|
Produces structured datasets (e.g., CSV, JSON) | |
| Legality/Ethics | Usually compliant with website policies | Must be mindful of legal and ethical considerations, including terms of service | |
| Frequency | Continuous; crawlers regularly revisit sites | Often one-time or scheduled based on specific needs |
In summary, Web crawler focuses on discovering and indexing web content for search engines, whereas web scraping is concerned with extracting specific data from web pages for analysis and application. Understanding these differences is essential for effectively using these processes during internet activities.
Popular Web Crawlers
Web crawlers play a vital role in the functioning of search engines and other data-driven applications. Here are some of the most popular web crawlers and their significance:
Googlebot
Googlebot is the primary web crawler used by Google. It is essential for indexing web pages and providing relevant search results to users. Googlebot continuously scans the web to discover new pages and update existing ones, ensuring that Google’s search index is accurate and up-to-date.
Bingbot
Bingbot is Microsoft’s web crawler, responsible for indexing web pages for the Bing search engine. Similar to Googlebot, Bingbot plays a crucial role in maintaining the search engine’s database. Its key features include:
- Comprehensive Coverage: Bingbot crawls a wide range of web pages to provide users with diverse search results, focusing on quality and relevance.
- Support for Rich Content: Bingbot is designed to understand and index various types of content, including images, videos, and rich snippets, enhancing the search experience.
Bingbot’s continuous efforts help Bing compete with other major search engines by ensuring users find valuable and timely information.
Yandex Bot
Yandex Bot is the web crawler for Yandex, Russia’s leading search engine. It serves a vital role in indexing web pages primarily for Russian-speaking users. Key aspects of Yandex Bot include:
- Localized Indexing: Yandex Bot focuses on indexing content relevant to Russian users, helping provide tailored search results that consider regional language and cultural factors.
- Diverse Content Types: Like other major crawlers, Yandex Bot indexes various content types, ensuring a broad range of information is available to users.
Yandex Bot’s targeted approach helps Yandex maintain its position as a key player in the Russian search engine market.
Conclusion
Web crawlers are vital components of the internet. They play an important role in indexing, organizing, and making web content accessible. They enable search engines to provide relevant and timely search results, support data collection for businesses and researchers, and facilitate content aggregation across various platforms.
Looking ahead, the future of web crawling is promising, with advances in artificial intelligence and machine learning. They tend to enhance the efficiency and accuracy of crawling processes. The rise of the Semantic Web will improve the understanding and categorization of web content, while ongoing improvements in handling dynamic and JavaScript-heavy pages will ensure crawlers can index the modern web effectively.
As technology continues to evolve, web crawlers will adapt to meet new challenges and opportunities, ultimately leading to a more connected and intelligent web. Embracing these advancements will ensure that web crawling remains a powerful tool for discovering and delivering valuable information in an increasingly complex digital landscape.
If you are looking to explore the wide internet space easily, contact NetNut today!
Frequently Asked Questions
How do web crawlers benefit search engines?
Web crawlers help search engines by indexing web pages, ensuring that users receive relevant and timely search results, and maintaining a comprehensive database of web content.
How do web crawlers handle duplicate content?
Web crawlers identify and manage duplicate content by using algorithms that detect similar pages, often prioritizing one version to index and filter out duplicates from their results.
What are ethical considerations for web crawlers?
Ethical considerations include respecting robots.txt rules, avoiding server overload through rate limiting, and ensuring sensitive information is not collected during the crawling process.






