Explore the top web scraping ML projects to boost your data science abilities. Gain insights from real-world examples & elevate your expertise now.
Importance of Web Scraping in Machine Learning Projects
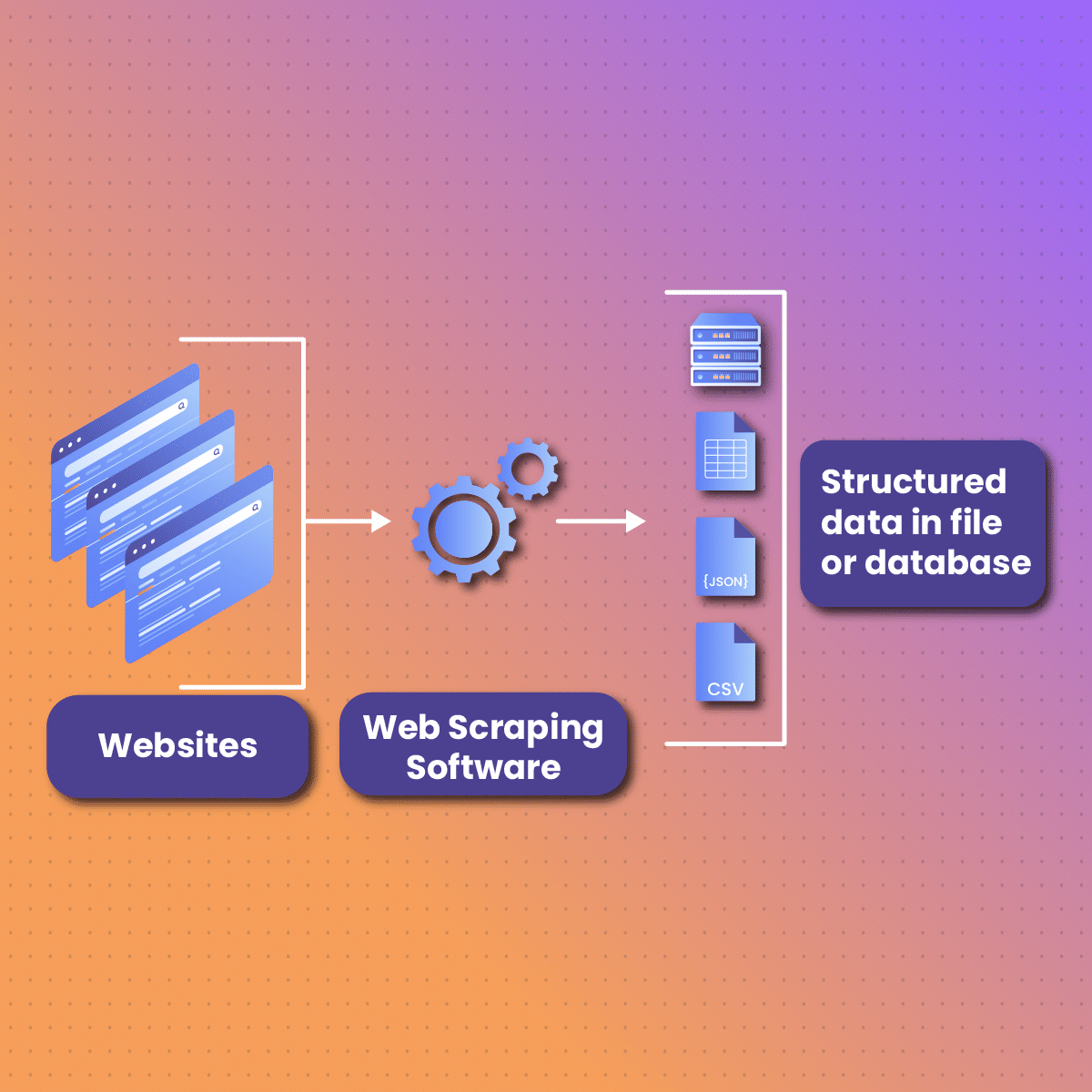
The importance of web scraping in machine learning projects cannot be overstated. Web scraping provides the raw data that machine learning models need to learn and make accurate predictions. It’s like the fuel for the machine learning engine. Without data, machine learning models can’t learn or predict anything.
Web scraping enables data scientists to gather large volumes of data from the internet quickly and efficiently. This data can then be cleaned, processed, and used to train machine learning models. The models can learn patterns from this data and use these patterns to make predictions or decisions. This makes web scraping an integral part of many machine-learning projects.
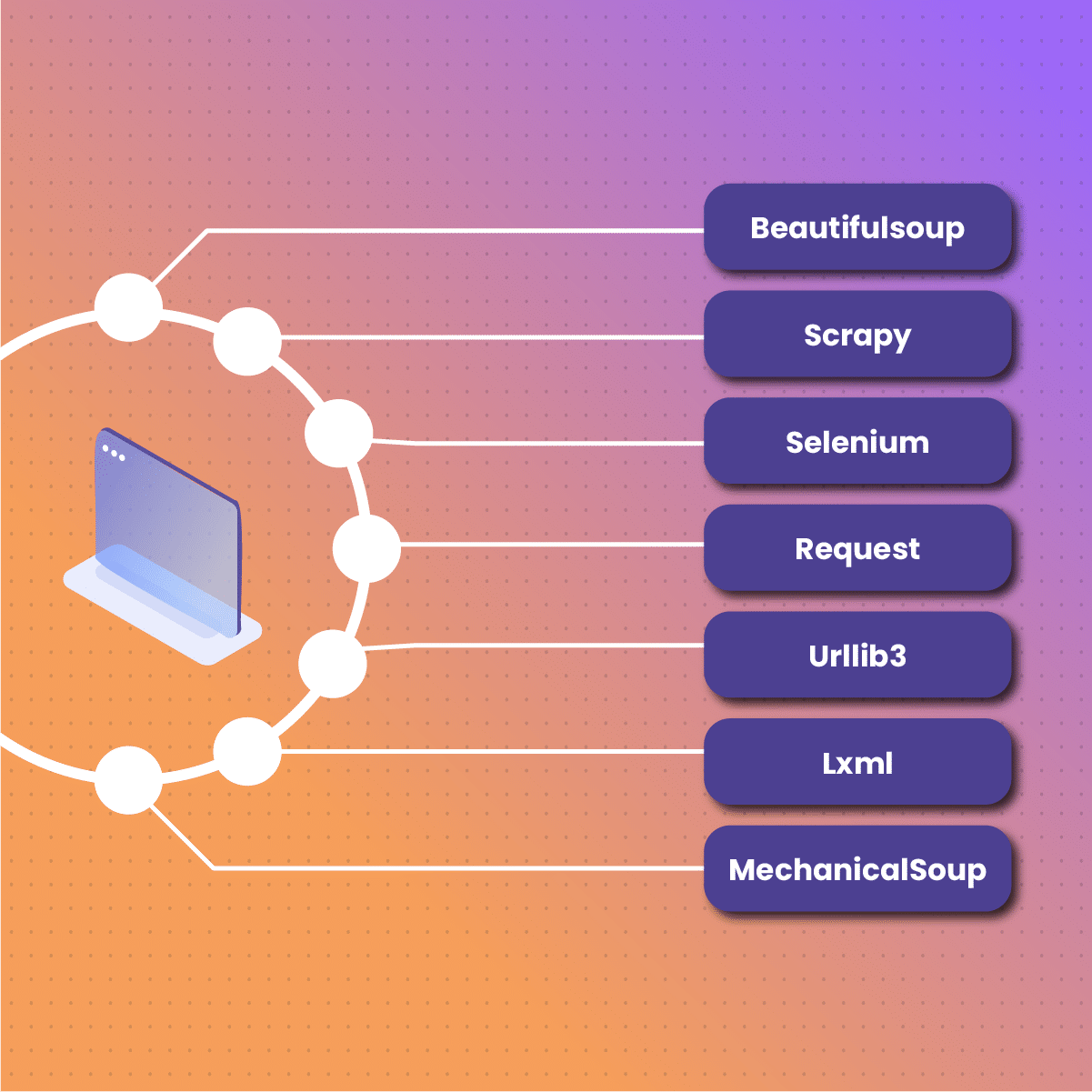
Popular Web Scraping Tools and Libraries for Machine Learning Projects
There are several popular web scraping tools and libraries that are commonly used in web scraping machine learning projects. These tools make it easier to extract data from websites and prepare it for machine learning algorithms.
Beautiful Soup
Beautiful Soup is a Python library for parsing HTML and XML documents. It creates a parse tree from page source code that can be used to extract data in a hierarchical and readable manner.
Scrapy
Scrapy is another Python library used for web scraping. It’s a powerful tool that can handle more complex scraping tasks and can also be used to build web spiders that crawl websites and extract data.
Selenium
Selenium is a tool primarily used for automating web applications for testing purposes, but it is also widely used in web scraping tasks. It is particularly useful when the data you need to scrape is located in JavaScript elements or when you need to interact with the webpage (like clicking a button).
Requests
Requests is a Python library used for making various types of HTTP requests. It’s a simple yet powerful tool for fetching data from the web.
lxml
lxml is a library for processing XML and HTML in Python. It’s very fast and easy to use and also compatible with both XPath and CSS selectors, making it versatile for web scraping tasks.
Top Web Scraping Machine Learning Projects (2024)
Web scraping machine learning projects are on the rise, particularly with the increasing emphasis on data-driven decision-making in businesses. Web scraping combined with machine learning enables innovative projects that leverage vast amounts of online data to derive meaningful insights. Here are some of the top web scraping machine learning projects in 2024.
Sentiment Analysis on Social Media Platforms
Social media platforms are a goldmine of user opinions and sentiments. By scraping social media data, businesses can gain insights into public opinion on their products or services. This project involves scraping data from social media sites to analyze public sentiment on various topics. By using natural language processing (NLP) and machine learning models, you can determine whether the sentiment expressed in posts or comments is positive, negative, or neutral. This analysis helps businesses understand customer perceptions and market trends.
Scraping social media data
The first step in this project is to scrape social media platforms for posts, comments, and reactions related to the business or product in question. This data can then be cleaned and structured for further analysis.
Performing sentiment analysis using machine learning algorithms
The scraped data can be used to train machine learning models to perform sentiment analysis.
These models analyze the sentiment behind social media posts, classifying them as positive, negative, or neutral. The results can help businesses understand public sentiment towards their brand, products, or services, helping them make informed decisions about marketing strategies or product improvements.
Job Market Trend Analysis
The job market is another area where web scraping and machine learning can provide valuable insights. By scraping job listings from job portals, data scientists can analyze trends in the job market and predict future trends. Job market trend analysis involves scraping job listings from various job boards and company websites to track employment trends, demand for specific skills, and geographic hiring patterns. Machine learning algorithms can then analyze this data to forecast job market changes, helping job seekers, recruiters, and policymakers make informed decisions.
Scraping job portals for job listings and requirements
Job portals are a rich source of information about job listings, required skills, salary ranges, and more. Web scraping can be used to extract this information from multiple job portals, providing a comprehensive view of the job market.
Analyzing job market trends using machine learning
The scraped data can be used to train machine learning models that analyze job market trends. These models can identify patterns in job listings, such as the most in-demand skills, the most common job titles, or salary trends. This information can be valuable for job seekers, recruitment agencies, and businesses alike.
These are just a few examples of how web scraping and machine learning can be combined in powerful and innovative ways. As we move further into the digital age, the possibilities for these technologies will only continue to expand.
Real Estate Price Prediction
Real estate is a field where data-driven insights can bring significant benefits. By leveraging the power of web scraping and machine learning, one can create projects that can predict property prices with a fair level of accuracy. Scraping real estate websites for data such as property prices, locations, features, and historical sales can help create a model to predict future property values. Machine learning algorithms can analyze this data to provide insights into market trends, enabling real estate agents, investors, and homebuyers to make better investment decisions.
Scraping real estate websites for property listings
Using web scraping, data related to property listings can be extracted from various real estate websites. This includes details like location, size, number of rooms, amenities, and asking price, providing a rich dataset for analysis.
Developing machine learning models for price prediction
Machine learning algorithms can be trained on this scraped data to predict property prices. These models can help buyers and sellers gauge the market better and make informed decisions.
News Article Classification and Summarization
News consumption in the digital age can be overwhelming. Web scraping and machine learning can help streamline this process through projects involving article classification and summarization. This project involves scraping news articles from various sources and using machine learning techniques to classify them into different categories like politics, sports, technology, etc. Additionally, summarization models can be applied to provide concise summaries of lengthy articles, making information consumption easier and quicker for users.
Web scraping news websites for articles
Web scraping can be employed to gather articles from various news websites. This process involves extracting the article text, author, publication date, and other relevant information.
Machine learning-based classification and summarization of articles
Machine learning models can be used to classify the scraped articles based on their content, and to generate concise summaries. This can provide users with a quick overview of the news landscape according to their interests.
E-commerce Product Recommendation System
E-commerce platforms thrive on providing personalized shopping experiences. One of the ways to achieve this is by developing machine learning-based product recommendation systems. An e-commerce product recommendation system uses web scraping to gather data on products, user reviews, and purchase histories from online retailers. Machine learning models analyze this data to suggest personalized product recommendations to users, enhancing their shopping experience and increasing sales for e-commerce businesses.
Scraping product data from e-commerce websites
Web scraping can be utilized to gather data from e-commerce websites, including product descriptions, reviews, and ratings. This data can serve as the foundation for a recommendation system.
Building a machine learning-based recommendation system
The scraped product data can be fed into machine learning algorithms to build a recommendation system. This system can then suggest products to users based on their browsing and purchasing history, enhancing the user experience and boosting sales.
Stock Market Prediction
Financial markets are rife with data that can be harnessed for predictive purposes. Web scraping and machine learning can be combined to create projects that predict stock market trends. Stock market prediction projects involve scraping financial news, stock prices, and historical market data to develop predictive models. Machine learning algorithms analyze this data to forecast future stock prices and trends, helping investors make informed decisions and manage risk more effectively.
Gathering financial data through web scraping
Financial data such as stock prices, company news, and economic indicators can be scraped from various online sources. This data serves as the input for predictive models.
Analyzing and predicting stock prices using machine learning algorithms
Machine learning models can be trained on the scraped financial data to predict stock price movements. These predictions can inform investment decisions, though it’s important to note that they cannot guarantee returns due to the inherent unpredictability of financial markets.
Sports Analytics and Player Performance Prediction
Sports analytics is a rapidly growing field where web scraping and machine learning are increasingly being used. These technologies can help in predicting player performance and game outcomes. Sports analytics projects use web scraping to collect data on player statistics, game results, and team performance from sports websites. Machine learning models then analyze this data to predict player performance, team outcomes, and even potential injuries, aiding coaches, analysts, and sports enthusiasts in making strategic decisions.
Scraping sports data from various sources
Data about player statistics, team performance, and game results can be scraped from sports websites and databases. This data is crucial for building predictive models.
Using machine learning to analyze player performance and game outcomes
Machine learning algorithms can be applied to the scraped sports data to predict player performance and game outcomes. These predictions can be useful for coaches, players, and sports enthusiasts.
Movie Rating and Review Analysis
The film industry can benefit from insights gained through web scraping and machine learning. Projects in this domain often involve analyzing movie ratings and reviews to predict movie success. This project focuses on scraping movie ratings and reviews from platforms like IMDb or Rotten Tomatoes to analyze audience preferences and sentiment. Machine learning models can process this data to predict movie success, identify trends in viewer preferences, and assist production companies in developing targeted marketing strategies and content.
Scraping movie ratings and reviews from various platforms
Web scraping can be used to gather movie ratings and reviews from various online platforms.
Building machine learning models to predict movie success
Using machine learning, the data scraped from various platforms can be analyzed to predict a movie’s success. Factors such as audience reviews, critic scores, and social media sentiment can be predictive of box office performance, making this an interesting application of web scraping machine learning projects.

Tips and Best Practices for Web Scraping in Machine Learning Projects
When embarking on web scraping projects for machine learning, there are certainly best practices and tips that can enhance the process and improve outcomes.
Ensuring data quality and accuracy
Data is the backbone of any machine learning project. Therefore, it’s crucial to ensure the data scraped from websites is accurate and of high quality. This involves cross-verifying data from different sources and cleaning the data before using it for model training.
Handling dynamic websites and AJAX content
Scraping dynamic websites and AJAX content can be challenging but is often necessary for gathering comprehensive data. Familiarity with tools like Selenium can help handle these scenarios effectively.
Respecting website terms of service and rate limiting
While scraping data from websites, it’s crucial to respect their terms of service and not overwhelm servers by sending too many requests in a short time. This not only maintains ethical standards but also prevents being blocked by the website.
Storing and preprocessing data for machine learning
Once data is scraped, it needs to be stored and preprocessed effectively for machine learning. This involves data cleaning, handling missing values, and transforming data into a suitable format for model training.
The Future of Web Scraping and Machine Learning in 2024 and Beyond
Looking forward, the integration of web scraping and machine learning holds immense potential. As data continues to grow in volume and variety, the demand for skills in these areas is only expected to increase.
The future will likely see more sophisticated web scraping techniques and advanced machine learning models. This will enable even more complex and insightful projects, pushing the boundaries of what we currently consider possible. The development of ethical guidelines and regulations for data scraping will also be a crucial aspect of this future, ensuring the practice is carried out responsibly and respectfully.
Whether you’re a seasoned data scientist or a beginner looking to break into the field, keeping an eye on the latest web scraping machine learning projects can provide valuable insights and inspiration for your own work. Always remember, the key to successful projects lies in understanding the data, applying the right techniques, and continuously learning and adapting.

Advantages and Disadvantages of Web Scraping Machine Learning Projects
Web scraping and machine learning, when combined, can produce powerful insights and drive significant advancements in various fields. However, like any technology, it has its advantages and disadvantages.
Advantages of Web Scraping Machine Learning Projects
Access to Large Amounts of Data
One of the major advantages of web scraping in machine learning projects is that it provides access to large amounts of data from the web. This data can be used to train machine learning models, resulting in better performance and more accurate predictions.
Automation and Efficiency
Web scraping allows for automation, which can greatly increase efficiency. Instead of manually gathering data, web scraping tools can do the work, saving significant time and effort.
Versatility
Web scraping provides versatility in terms of the types of data that can be collected. It can be used to scrape data from various types of websites and in various formats.
Disadvantages of Web Scraping Machine Learning Projects
Legal and Ethical Considerations
One of the major challenges in web scraping is navigating legal and ethical considerations. Not all websites allow their data to be scraped, and doing so without permission can lead to legal consequences.
Data Quality Issues
Web scraping can sometimes lead to data quality issues. Since the data is being scraped from websites, there’s a risk of collecting inaccurate or incomplete data, which can negatively impact the performance of machine learning models.
Difficulty in Scraping Dynamic Websites
Websites that rely heavily on JavaScript or AJAX to load content can be challenging to scrape. This may require more advanced techniques and tools.
Below is a comparison table summarizing the advantages and disadvantages of web scraping machine learning projects:
| Advantages | Disadvantages |
| Access to large amounts of data | Legal and ethical considerations |
| Automation and efficiency | Data quality issues |
| Versatility | Difficulty in scraping dynamic websites |
Resources
- Towards Data Science: This blog covers a wide range of topics related to data science, including web scraping and machine learning. It features articles written by experts in the field and provides valuable insights and tutorials for beginners and advanced practitioners alike.
- Real Python: This website offers a variety of Python tutorials, including ones on web scraping and machine learning. Their articles are written by experienced developers and are designed to be easy to follow.
- FreeCodeCamp: An online learning platform that offers courses on web development and data science, including topics such as web scraping and machine learning. Their courses are free and self-paced, making it easy for learners to follow along at their own pace.
- Kaggle: A platform that hosts data science competitions and provides access to datasets and tools for machine learning. It’s a great place to practice your web scraping and machine learning skills while also engaging with a community of data science enthusiasts.
- Machine Learning Mastery: A blog that provides tutorials, guides, and resources for machine learning practitioners. The site includes articles on web scraping and data preparation, as well as tutorials on machine learning algorithms and techniques.






