Introduction To Web Scraping and Web Crawling
About 5.3 billion people use the internet as of October 2023, and they generate data on the websites they visit.
Many businesses have a website with several web pages. These web pages are home to data that serves a number of purposes. This relationship between websites and data is critical because it aids web scraping and web crawling.
These two concepts are often confused since they sound quite alike. Although web scraping and web crawling have some similarities, they have different mechanisms of action. Confusion usually arises because both processes are critical for web data extraction.
This guide will examine web scraping vs web crawling, their similarities, differences, common challenges, use cases, and how their efficiency can be optimized with NetNut proxies.
Web Scraping vs Web Crawling
In order to understand the difference between scraping and crawling, we need to understand the exact definitions of each:
What Is Web Scraping?
Web scraping, also known as web data extraction, is collecting data from one or more web pages. Unlike simply viewing or copying data manually, web scraping automates this process, enabling users to gather large amounts of information quickly and efficiently. This technique is often used for various purposes, including market research, price comparison, content aggregation, and competitive analysis. It can be done manually by copying and pasting- only suitable for small tasks. Alternatively, if you need to collect large datasets, you may need a scraping tool.
Data collected from web scraping can be converted into structured formats like XML, JSON, CSV, and more to aid data organization and analysis. Web scraping typically involves making HTTP requests to access web pages, then parsing the HTML content to extract the relevant information. The data extracted can range from text and images to more complex elements like product details, reviews, or metadata. By automating the collection of web data, scraping allows businesses and researchers to stay informed and make data-driven decisions based on up-to-date information from multiple sources.
What Is Web Crawling?
Web crawling is the process of systematically browsing the internet to index content from websites, much like how search engines like Google operate. A web crawler, also known as a spider or bot, starts from a set of URLs and follows links on those pages to discover and index new content. The primary goal of web crawling is to build an extensive index of web pages that can be searched and accessed later.
On the other hand, web crawling involves using spiders or bots to index all the information on a web page. If you have a website, it is necessary to identify which pages are indexed with Google index coverage. Subsequently, you can identify web pages with errors that prevent crawling spiders from identifying them.
Web crawling allows web spiders to search and index web content on the internet automatically. This is necessary to provide updated and relevant responses to search engine queries. Subsequently, the goal of web crawling is to understand the content of a web page. Crawlers are designed to visit websites, read their content, and follow hyperlinks to continue exploring the web. This process is repeated across thousands or even millions of pages, creating a comprehensive database of web content.
Web crawling is crucial for search engines, which rely on these indexed pages to deliver relevant search results to users. It can also be used for monitoring website changes, gathering data for analytics, or feeding content to other applications and services.
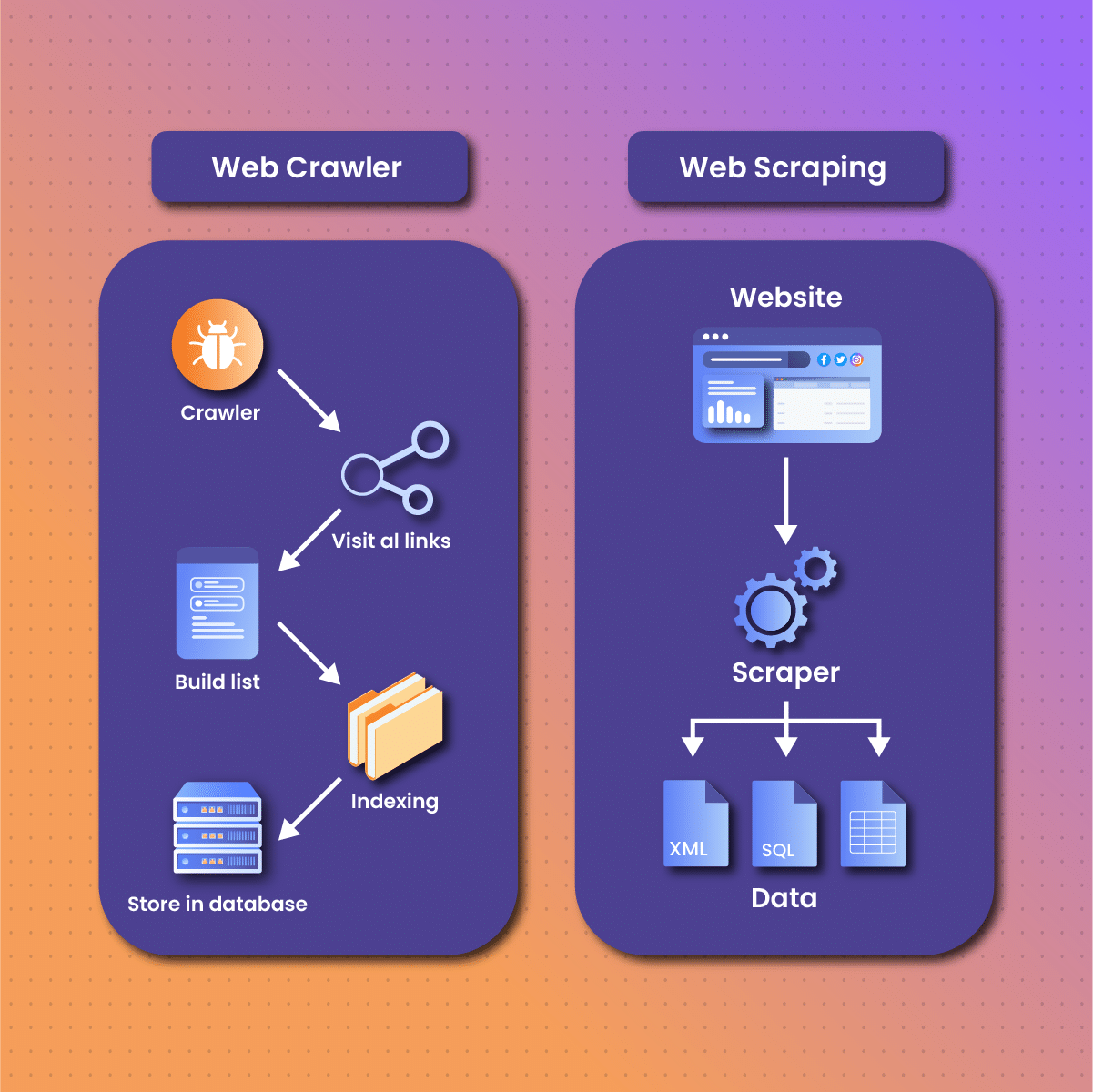
How Do Web Scrapers and Web Crawlers Work?
In the debate regarding web scraping vs web crawling, we have examined their definitions. Therefore, in this next section, it becomes critical to discuss how web scraping and web crawling work.
How does web scraping work?
Web scraping works by automating the process of accessing web pages and extracting specific data from their content. The process begins with sending HTTP requests to the target website to retrieve its HTML code. Once the HTML is obtained, the scraper parses the code to locate and extract the desired data. This is typically done using programming languages like Python, with libraries such as BeautifulSoup, Scrapy, or Selenium being popular choices for this task.
The extracted data can include anything from plain text and images to more complex elements like tables or JSON responses from APIs. Once the data is collected, it is cleaned, organized, and stored in a structured format, such as a CSV file or database, making it easy to analyze and use for various applications.
To avoid detection and ensure efficient data collection, scrapers often implement techniques such as IP rotation, using proxies, and respecting website crawling policies defined in the robots.txt file. Additionally, advanced scrapers can handle dynamic content, interact with JavaScript, and even simulate user actions to access data that is not readily available in the HTML source.
The first step is identifying the target website containing the data we want to extract. Next, the web scraper sends a request and extracts the required data from the websites. In addition, the data can be stored in your preferred format, such as JSON or XML.
In simpler terms, a web scraping code has three components including:
- A web crawling constituent that sends a request to target websites
- A component that extracts and parses data
- A component that saves and exports data
How does web crawling work?
Web crawling works by using automated bots, known as crawlers or spiders, to explore the internet in a systematic way. The crawler begins by visiting a set of predefined URLs and then follows the links on those pages to discover additional web pages. This process is recursive, allowing the crawler to navigate through a vast network of linked content across the web.
As the crawler visits each page, it reads the HTML content, which includes text, metadata, links, and other embedded elements. The information is then indexed and stored in a database, where it can be retrieved and analyzed later. Web crawlers are designed to prioritize certain pages, often based on factors like page authority, content freshness, and relevance to specific keywords or topics.
Because web crawlers are designed to explore the web extensively, they must be efficient and capable of handling large-scale data collection without overwhelming servers. To manage this, crawlers often implement rate limiting, obey robots.txt directives, and use distributed crawling strategies to cover vast amounts of content while minimizing the load on individual websites.
The function of a web crawling bot is to gather URLs, which it analyzes by checking the hyperlinks and meta tags. After the web crawling spider has indexed all the content on each web page, it saves the indexed data in the database. Meanwhile, the web crawler adds the identified hyperlinks to a queue for crawling later.
Use Cases of Web Scrapers and Web Crawlers
Web scraping and web crawling are two unique techniques that can significantly affect your business’s growth. Regardless of their synergy, they have different applications, which we will examine in this section.
Use Cases of Web scraping
Web scraping is becoming increasingly significant for e-commerce businesses. Here are some applications of web scraping, especially for businesses:
Price monitoring
One of the most common use cases of web scraping is price monitoring. This function allows businesses to compare prices with competitors. Competitive pricing allows your business to thrive in the highly competitive e-commerce space.
However, price scraping is controversial as it often results in malicious scraping. This happens when a server is overloaded with requests for price scraping, especially since many people want real-time price updates.
Brand monitoring
Another popular application of web scraping is brand monitoring which is critical for brand protection. If you can monitor competitor sites, you can also get updated information on your brand. This is especially important if your brand is always on the news.
Another aspect of brand monitoring is scraping data on reviews. You can use NetNut Social Scraper to gather data that provides meaningful insights on public sentiment. Subsequently, your brand can address any issues appearing as a negative review.
In addition, web scraping allows your brand to monitor, identify, and take necessary legal actions against cybercriminals guilty of brand abuse.
Lead Generation
Lead generation is another critical use case of web scraping. Lead generation can be a major challenge because there is a high chance that people around don’t know you offer such services. Therefore, businesses can extract data from publicly available customer databases, including email addresses and contact information.
This information can be used as part of a cold calling/emailing strategy to increase brand awareness and boost sales. This function is especially beneficial to new businesses looking to increase their customer base within the first few months.
Monitoring competition
Web scraping allows brands to monitor their competition to remain relevant in the industry. Competition is fierce, and companies are constantly thinking of innovative ways to stand out and optimize customer experience and satisfaction.
Therefore, keeping track of competitors’ SEO and marketing strategies becomes critical. Doing this manually can be frustrating and not provide the desired results. However, a web scraping bot can automate the process. In addition, you can use web scraping to collect data on ratings, reviews, and product descriptions.
Use Cases of Web Crawling
Web crawling is suited for tasks that involve collecting URLs. Here are some common applications of web crawling:
Indexing
Many people rely on search engines like Google, Yahoo, and Bing to get information about various subjects, including healthcare, fitness, recipes, fashion, and more. These search engines deploy web crawlers to find new pages or updated content. Subsequently, the information they find in the index is stored in the database.
Now, why is this relevant? This activity ensures that when you (the users) ask the search engine a question, it can provide answers based on their relevance. As a result, it makes accessing accurate information faster.
Optimizing your website performance
If you have a website, you need web crawling to determine its performance and optimize it as necessary. Web crawling allows you to detect issues that could have a significant negative impact on the website’s SEO performance.
These issues may include broken links, images without ALT text, meta tags, or meta descriptions. In simpler terms, web crawling allows you to identify loopholes in your website structure that could affect its performance. Web crawling can serve as an automated website maintenance tool as it checks for navigation errors.
Competitor’s SEO
Apart from analyzing your website, you can use web crawling to analyze competitor’s websites for SEO purposes. As a result, you are always well-informed about new SEO strategies and how they can benefit your business.
Checking host and service freshness
Most website pages rely on external hosts and services. However, the providers of these external services may experience some downtime, which directly affects the performance of the website.
So, what is the way out? Web crawlers can be used to check for host and service freshness- a measure of their uptime calculated with a freshness threshold.
Subsequently, you can determine which hosts and services are stable and fresh by using a web crawler to periodically ping each host/service and compare them to the freshness threshold.
Web scraping
Well, you heard or read that right! This is undoubtedly an important point in our discussion of web scraping and web crawling. All web scrapers work with web crawling, but web crawlers don’t use web scrapers.
Each web scraper bot usually has a built-in module that first crawls the websites it needs to extract data from. Subsequently, without web crawling, it will be more challenging for the scraping bot to find relevant web pages.
Key Differences Between Web Crawling and Web Scraping
Below is a table of some of the most important differences between scraping and crawling:
|
Web Scraping |
Web Crawling |
|
|
Definition |
This is a process of extracting data from websites with web scraping tools that imitate human browsing patterns |
This is an automated process of indexing information on the web and storing them in a database |
|
Aim |
The aim is to retrieve data from target websites |
Search and index web pages for search engine result page |
|
How it works |
The bot parses the HTML content to extract data using the instructions written in the code |
The web crawler follows links to build a map of URLs |
|
Result |
Data in structured formats like CSV, XLM, or JSON |
A list of web pages |
|
Performed by |
Web scraping bot |
Automated web crawlers |
|
Application |
Analyze web pages |
Understand web page by search engines |
|
Scalability |
It can be used on small and large scale |
It is mostly used for large scale processes |
|
Data analysis |
Data is often extracted in a structured format which makes it easy to perform data analysis |
Data analysis is not applicable to web crawling |
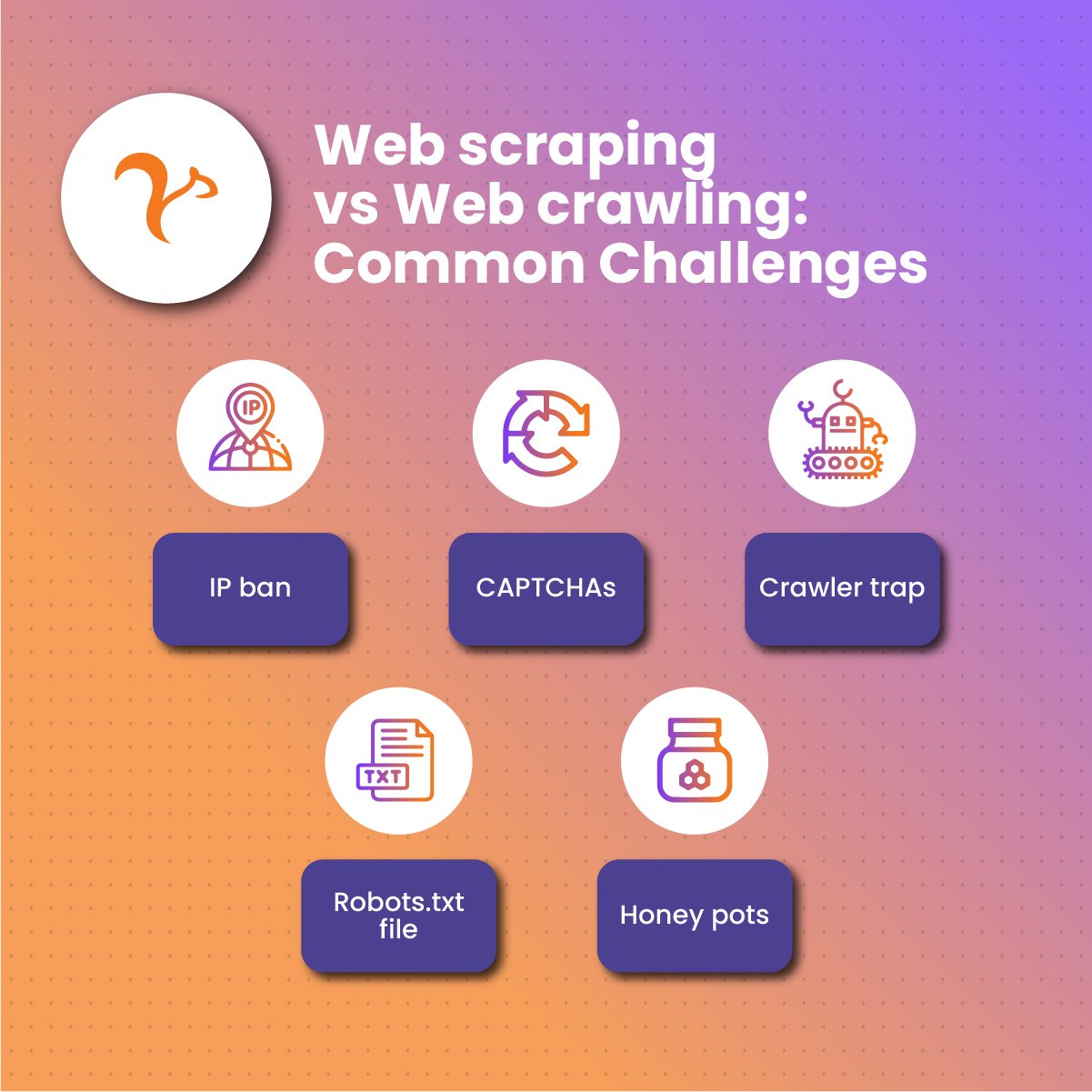
Common Challenges That Web Scrapers and Web Crawlers Face
Web scraping and web crawling are automated processes that involve accessing resources on the web. Therefore, they have some similar challenges, including:
IP ban
Since websites want to protect the integrity of their data, they usually implement anti-scraping measures. IP bans/blocks are among the most common challenges for web scraping and web crawling. Subsequently, if you send too many requests to a server, the anti-scraping measures are triggered, which can lead to an IP ban. As a result, you will be unable to access real-time data, which may be necessary for organizations that require updated data regularly.
CAPTCHAs
CAPTCHAs are popular techniques to detect web scraping and web crawling bots. It stands for Completely Automated Public Turing Tests To Tell Computers and Humans. Websites often employ this measure, which requires manual interaction to solve a puzzle before accessing specific content. It could be in the form of text puzzles, image recognition, or analysis of user behavior.
However, you can avoid this problem by implementing CAPTCHA solvers into your web scraping code to avoid this issue. Ultimately, this may potentially slow down the process of web data extraction. Using NetNut proxies is a secure and reliable way to bypass CAPTCHAs.
Crawler trap
Crawler trap, also known as spider trap, is designed to mislead web crawlers. As a result, web crawling bots fetch malicious pages, including spam URLs, instead of actual websites. Consequently, it triggers an infinite loop where the malicious pages dynamically generate spam links and redirect crawlers to this link so it gets stuck within the spam web pages.
Robots.txt file
Most websites have a robot.txt file, which provides a comprehensive guide on data that can be publicly used. As a result, it gives you an overview of what data to extract and those to avoid. Subsequently, this guides you in writing the code for your web scraping and web crawling bots.
A web page robots.txt file may indicate that scraping content from a certain page is prohibited. Therefore, your activities may be categorized as malicious and illegal if you proceed against the instruction.
Honey pots
Honeypot is a trap aimed to discover web scraping and web crawling bots. It could involve elements or links only visible to bots and not humans. Therefore, if a web scraping bot or web crawling bot accesses such an element or link, it falls into the trap. Subsequently, the website can identify the bot and block your IP address.
How to Optimize Web Scraping vs Web Crawling with NetNut
Web scraping and web crawling are automated processes with similar challenges. Meanwhile, we have examined the significance of both processes to your business. Therefore, examining a solution that can optimize the efficiency of web scraping and web scraping is critical. This is where NetNut proxies come into play.
NetNut is a global solution that provides various proxies to cater to your specific data extraction needs. These proxies serve as intermediaries between your device and the website that holds the data.
NetNut has an extensive network of over 52 million rotating residential proxies in 195 countries and over 250,000 mobile IPS in over 100 countries, which helps them provide exceptional data collection services.
NetNut rotating residential proxies are your automated proxy solution that ensures you can access websites despite geographic restrictions. Therefore, you get access to real-time data from all over the world that optimizes decision-making.
In addition, you can use our in-house solution- NetNut Scraper API, to access websites and collect data. Moreover, you can use NetNut’s Mobile Proxy if you need customized web scraping solutions.
The various proxy solutions are designed to help you overcome the challenges of web scraping for effortless results. These solutions are critical to remain anonymous and prevent being blocked while your web scraping and web crawling bots do what they need to do.
How To Choose Between Web Scraping and Web Crawling
Choosing between web scraping and web crawling depends on your specific goals and the type of data you need. If your objective is to extract specific information from a set of known web pages or a particular website, web scraping is the most appropriate tool. Scraping allows you to target and collect precise data, such as product prices, user reviews, or article content, making it ideal for applications where structured data is required for analysis or reporting.
On the other hand, if your goal is to discover and index a broad range of web content across multiple sites, web crawling is the better option. Crawling is useful for creating large-scale databases of web pages, monitoring website changes, or building a search engine index. Crawlers are designed to explore the web comprehensively, capturing data from a wide array of sources and following links to uncover new content.
In some cases, a combination of both techniques may be necessary. For example, you might use web crawling to identify and index relevant pages across multiple sites, then apply web scraping to extract specific data from those pages. The choice between web scraping and web crawling ultimately depends on the scope of your project, the nature of the data you need, and how you plan to use that data.
Final Thoughts on Using Web Scrapers vs Using Web Crawlers
This guide has examined web scraping vs web crawling- definitions, how they work, differences, applications, challenges, and effective strategies to overcome them.
Web scraping aims to extract data from targeted sites and store them in a structured format like JSON, CSV, and others. Meanwhile, web crawling aims to find and index new website pages. Therefore, a web crawling bot has to go through every page and link on a website and index them.
Although web scraping and web crawling are often misused, their applications are quite distinct. Price monitoring, brand monitoring, and lead generation are some of the common applications of web scraping. On the other hand, indexing, automatic website maintenance, and checking host and service freshness are the most common use cases of web crawling.
Finally, the use of proxies has become a critical aspect of web scraping and web crawling. It opens the door to new possibilities for both processes. Therefore, we recommend using the NetNut proxy server provider- your satisfaction is our priority.
Kindly contact us if you have any questions about choosing the best proxy solution for your needs.
Frequently Asked Questions
What is the significance of web crawlers for SEO?
SEO- Search engine optimization aims to optimize a website’s visibility when people search for related products and services. Some websites may rank low or simply not show on the SERP search engine result page because they contain errors that make them difficult or impossible to crawl.
For example, a website with errors like a broken link may not be accessible to a crawling bot. As a result, it will not appear on the search engine result page. In addition, regular crawling by bots is necessary to identify changes that may increase SEO ranking, especially for time-sensitive content.
What are some examples of web crawlers?
Most search engines have bots for web crawling. They include:
- Google – Googlebot
- Bing – Bingbot
- Yahoo – Slurp
- DuckDuckGo – DuckDuckBot
- Baidu – Baiduspider
- Exalead – ExaBot
What is the primary difference between web scraping and web crawling?
Web scraping and web crawling are two critical processes for web data collection. Web scraping involves retrieving data from a website, while web crawling involves the discovery of URLs and gathering pages to create indices.






