Introduction
Web scraping has evolved into an essential tool for extracting critical information from websites. The demand for powerful web scraping solutions grows in tandem with the evolution of the digital ecosystem. Web scraping is a powerful tool for collecting, analyzing, and exploiting data from the web, whether you’re a data scientist or a business analyst.
BeautifulSoup, a Python library, comes into action here. BeautifulSoup is a feature-rich library designed for pulling data out of HTML and XML files. Its simplicity and flexibility make it a favorite among developers for parsing HTML and navigating the parse tree, making the extraction of data from web pages seamless.
As websites evolve, BeautifulSoup’s adaptability ensures that your web scraping scripts remain robust and reliable. However, many websites employ anti-scraping measures to protect their data from being harvested by automated bots. This is where NetNut, an advanced proxy service, steps in to elevate your web scraping capabilities.
This guide will explore the basics of BeautifulSoup and how to integrate it with NetNut proxy servers.
Understanding BeautifulSoup
BeautifulSoup is a Python library that provides tools for web scraping HTML and XML files. Developed by Leonard Richardson, BeautifulSoup sits on top of an HTML or XML parser and provides Pythonic idioms for iterating, searching, and modifying the parse tree. It is widely used for pulling data out of HTML and XML files in a way that is both efficient and intuitive.
One of BeautifulSoup’s key strengths is its simplicity. It transforms complex HTML documents into a tree of Python objects, such as tags, navigable strings, or comments. This hierarchical structure allows developers to navigate and manipulate the HTML easily.
Installation and Setup
Before using BeautifulSoup, you need to install it using a package manager like Pip. The following command will install BeautifulSoup:
![]()
Once installed, you can import it into your Python script:

Basic HTML Parsing with BeautifulSoup
BeautifulSoup supports various parsers, including the built-in Python parser (*html. parser*), xml, and html5lib. The choice of parser depends on the specific project requirements. To parse an HTML document with BeautifulSoup, you typically start by creating a BeautifulSoup object, passing the HTML content and the chosen parser as parameters:

Navigating the HTML Tree Structure
Once you have the BeautifulSoup object, you can navigate the HTML tree structure using various methods. The two primary navigation methods are:
- Tag-based navigation: This allows you to access tags directly.
![]()
- Searching the tree: This allows you to search for tags based on criteria.
![]()
The need to navigate the tree structure becomes crucial when dealing with complex HTML documents where data is distributed across different tags and elements.
Extracting Data with BeautifulSoup Methods
BeautifulSoup provides a variety of methods for extracting data from HTML. Some of the commonly used methods include:
- .text and.string: To retrieve the text content within a tag.
![]()
- .get: To retrieve the value of an attribute within a tag.
![]()
- .find and.find_all: To search for tags that match specific criteria.
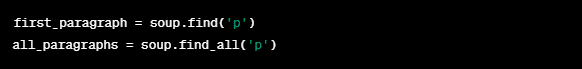
These methods make it easy to extract specific data points from a webpage using BeautifulSoup, while providing the foundation for more advanced web scraping tasks.
Integrating BeautifulSoup Library with NetNut
Introduction to NetNut and Its Features
NetNut stands out among proxy services with its unique approach to providing residential IPs. Unlike traditional proxies that might use data center IP addresses, NetNut utilizes a residential proxy network. This means that the IP addresses come from real residential devices, making them more difficult to identify as proxies.
The key features of NetNut include:
- Residential IPs: NetNut’s residential IPs are sourced from real devices, making them less likely to be detected and blocked.
- Global Coverage: NetNut offers a wide range of IP addresses from different countries, allowing you to access geo-restricted content and gather data from diverse locations.
- High Performance: NetNut’s infrastructure is designed for speed and reliability, ensuring that your web scraping operations are efficient.
- Easy Integration: NetNut provides a simple API that allows for easy integration into your web scraping scripts, making it accessible to both beginners and experienced developers.
Incorporating NetNut into your BeautifulSoup web scraping workflow not only increases the effectiveness of your data extraction but also provides a level of security and anonymity crucial in the ever-evolving landscape of the internet. Let’s explore how to seamlessly integrate NetNut with BeautifulSoup to supercharge your web scraping capabilities.
Configuring NetNut Proxy Settings
Before integrating NetNut with BeautifulSoup, you need to configure the proxy settings by obtaining your NetNut API key. Follow these steps to set up NetNut:
- Create an account on the NetNut website and obtain your API key.
- Then install the NetNut Python Package. Use the following command to install the NetNut Python package

- The next step is to incorporate NetNut into your BeautifulSoup web scraping script by setting up the proxy with your API key.
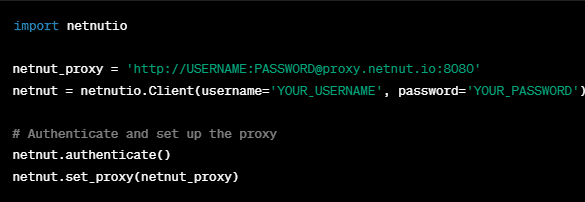
NB: Replace ‘YOUR_USERNAME’ and ‘YOUR_PASSWORD’ with your NetNut credentials.
Implementing Proxy Rotation for Efficient Scraping
NetNut’s strength lies in its ability to rotate through a vast pool of residential IPs, minimizing the risk of being blocked. Implementing proxy rotation in your web scraping script is straightforward.
Handling Common Web Scraping Challenges with NetNut
Highlighted below are ways to handle rate limiting, and geo-restrictions, and ensure secure data retrieval with NetNut.
- Anti-Scraping Measures: NetNut’s residential IPs reduce the likelihood of being flagged by websites employing anti-scraping measures. The rotation of IPs further mitigates the risk of IP bans.
- Rate Limiting: Proxy rotation allows you to distribute requests across multiple IPs, helping to overcome rate limiting imposed by websites.
- Geo-Targeting: NetNut’s global coverage allows you to access websites from different geographic locations, enabling geo-targeted scraping. This feature ensures you have unlimited access to website contents regardless of your location
- Data Security: NetNut ensures a secure connection between your scraper and the target website, safeguarding the integrity of your data retrieval process.
Advanced Techniques for Optimizing BeautifulSoup Web Scraping Performance
To elevate your web scraping with BeautifulSoup, explore these cutting-edge strategies. From selective scraping to asynchronous techniques, delve into advanced methods to optimize performance.
Use Selective Scraping
Instead of scraping entire web pages, target specific elements and data points relevant to your needs. This reduces the amount of data to process, improving performance.
Asynchronous Scraping
Employ asynchronous BeautifulSoup libraries like asyncio and aiohttp to make concurrent requests. This can significantly speed up your scraping process by allowing multiple requests to be processed simultaneously.
Caching Responses
Implement caching mechanisms to store previously scraped data locally. This reduces the need to re-scrape the same data, saving time and resources.
Optimize HTML Parsing
Choose the most suitable parser for your specific project. The lxml parser, for example, is often faster than the built-in HTML.parser.
Use Session Objects
When making multiple requests to the same website, utilize session objects with requests. This maintains persistent connections and can improve performance by reusing TCP connections.
By seamlessly integrating NetNut with BeautifulSoup, you not only enhance your web scraping capabilities but also navigate and overcome common challenges associated with scraping at scale.
Debugging and Troubleshooting with BeautifulSoup and NetNut
Whether you’re a beginner or an experienced developer, navigate through common challenges, and elevate your data scraping game via BeautifulSoup to ensure a seamless and error-free data extraction experience with this comprehensive.
Print and Inspect HTML
Output the HTML content of the page you’re scraping using print(response.text) or similar methods. Inspect the HTML structure to ensure your BeautifulSoup selectors are accurate.
Use Beautiful Soup’s prettify()
The prettify() method in BeautifulSoup makes the HTML structure more readable. This is invaluable for debugging and understanding the page structure.
Check HTTP Status Codes
Inspect the HTTP status codes returned by your requests. A status code of 200 indicates a successful request, while 403 or 404 might suggest issues with access or page availability.
Implement Logging
Incorporate logging in your scripts to track errors, warnings, and other relevant information. This helps in identifying and addressing issues efficiently.
Test with Small Samples
When developing or debugging a script, test it with a small sample of data or a limited number of pages. This allows you to identify and resolve issues before scaling up your scraping operation.
With continuous practice, the combination of BeautifulSoup and NetNut proves to be a potent duo in web data extraction.
Best Practices for Ethical Web Scraping
Before diving into BeautifulSoup web scraping, it’s crucial to understand some ethics that guarantee secure and smooth web scraping. This includes respect for the terms of service of the websites you intend to scrape. Websites often have guidelines that dictate how their data can be used and accessed. Some may explicitly prohibit scraping, while others may provide specific rules to follow. Violating these terms not only raises ethical concerns but may also lead to legal consequences.
To ensure ethical web scraping:
- Review Terms of Service: Carefully read and understand the terms of service of the website you plan to scrape. Look for any information related to scraping or data usage policies.
- Check for a Robots.txt File: The robots.txt file on a website often contains rules for web crawlers and scrapers. Respect the directives in this file to ensure compliance with the website’s guidelines.
Implementing Rate Limiting and Delays
Web scraping with BeautifulSoup etiquette involves being considerate of the server’s resources and minimizing the impact of your scraping activities. Implementing rate limiting and delays is a best practice to avoid overwhelming the server and to simulate more human-like behavior.
Consider the following practices:
- Set Request Intervals: Space out your requests by implementing delays between consecutive requests. This prevents sending too many requests in a short period, reducing the risk of being flagged as suspicious.
- Randomize Delays: Introduce randomness in your delay intervals to make your scraping behavior less predictable. This can help mimic natural user interactions.
Handling Dynamic Content and AJAX Requests
Modern websites often use dynamic content loading techniques, such as AJAX, to enhance user experience. When web scraping, it’s essential to handle these dynamic elements to ensure that you capture all relevant data.
Best practices for handling dynamic content:
- Use Headless Browsers: Headless browsers, such as Selenium, allow you to simulate the interaction of a real user with the website. This is particularly useful for scraping content loaded via JavaScript.
- Inspect Network Requests: Use browser developer tools to inspect network requests and identify AJAX calls. Mimic these requests in your scraping script to retrieve dynamically loaded content.
Avoiding Common Pitfalls and Legal Issues in Web Scraping
Web scraping with BeautifulSoup, if not done responsibly, can lead to legal issues and damage your reputation. Avoid common pitfalls and adhere to legal guidelines with these best practices:
- Check for Legal Restrictions: Some websites explicitly prohibit scraping in their terms of service. Respect these restrictions to avoid legal consequences.
- Identify Yourself: Include a user-agent string in your HTTP requests to identify your scraper. This allows website administrators to contact you if there are issues with your scraping activities.
- Avoid Overloading Servers: Do not overwhelm servers with too many requests. Stick to reasonable and ethical scraping practices to ensure that the server’s performance is not adversely affected.
- Monitor Changes: Regularly check if the website’s structure or terms of service have changed. Adjust your scraping scripts accordingly to maintain compliance.
With these practices, you not only ensure ethical and responsible web scraping with BeautifulSoup but also reduce the likelihood of encountering legal issues or being blocked by websites. Responsible BeautifulSoup data scraping is not only about extracting data efficiently but also about maintaining a positive relationship with the online community and respecting the rights of website owners.
Real-world Application Of Web Scraping with BeautifulSoup and NetNut
Highlighted below are a couple of real-world web scraping projects using the powerful combination of BeautifulSoup and NetNut.
E-commerce Product Price Monitoring
Objective: Track and monitor the prices of products on various e-commerce websites.
Implementation: Use BeautifulSoup to scrape product prices, descriptions, and reviews. Incorporate NetNut for proxying to prevent IP bans and increase the number of requests you can make without being detected.
Outcome: You obtain real-time data on product prices, analyze trends, and make informed decisions based on market dynamics.
Job Market Analysis
Objective: Gather data on job postings from different job boards to analyze the demand for specific skills in the job market.
Implementation: Utilize BeautifulSoup to scrape job postings, company information, and required skills. Integrate NetNut to rotate through residential IPs, avoiding IP bans and ensuring uninterrupted data collection.
Outcome: You gain insights into job market trends, identify in-demand skills, and make informed career decisions.
These real practical applications highlight the versatility and effectiveness of using BeautifulSoup and NetNut in combination for web scraping projects. From market analysis to competitive intelligence, the integration of these tools empowers users to extract valuable data ethically and efficiently, contributing to data-driven decision-making in various industries.
Conclusion
On final thoughts, the synergy between BeautifulSoup and NetNut presents a dynamic duo for web scraping beginners and professionals alike. BeautifulSoup’s simplicity and flexibility make it an ideal choice for parsing HTML and navigating the complex structures of web pages. When coupled with NetNut’s advanced residential proxy network, web scrapers gain a significant advantage in terms of anonymity, security, and scalability.
It is safe to say that the combination of these tools not only empowers users to extract valuable data efficiently but also helps to overcome challenges associated with anti-scraping measures and dynamic content. By embracing responsible practices and staying abreast of best practices and updates, we can harness the full potential of web scraping, unlocking insights, and driving innovation across various domains.
The journey of mastering web scraping with BeautifulSoup and supercharging it with NetNut is an exciting and rewarding endeavor, opening doors to a wealth of possibilities in the realm of data extraction and analysis. Web Scrape safely!
Frequently Asked Questions
How does BeautifulSoup contribute to web scraping?
BeautifulSoup is a Python library that simplifies the parsing of HTML and XML files. It provides tools for navigating the parse tree, searching for specific tags, and extracting data with minimal code. BeautifulSoup’s flexibility and ease of use make it a powerful ally in web scraping projects.
What role does NetNut play in enhancing web scraping capabilities?
NetNut is an advanced proxy service that supercharges web scraping by providing a residential proxy network. Its unique approach involves using IP addresses from real residential devices, making them less likely to be flagged by anti-scraping mechanisms. NetNut enhances anonymity, security, and scalability in web scraping.
How can I integrate NetNut with BeautifulSoup for web scraping?
To integrate NetNut with BeautifulSoup, you need to configure the NetNut proxy settings using your API key. Once configured, you can use NetNut’s proxy in your web scraping script by making HTTP requests through their proxy servers. This integration enhances your ability to gather data without the risk of being blocked.






