Introduction
The explosive growth of ecommerce in recent years has led to a steady increase in the number of websites. A website usually contains web pages that contain data. The relationship between websites and data is crucial because it is significant for web crawling and web scraping.
Getting data from websites across the world or in a specific location has become a critical part of operations. Organizations that utilize data for critical decision-making are 23x more likely to acquire customers, 6x as likely to retain customers, and 19x more likely to be profitable.
However, a common confusion arises as many use web crawling and web scraping interchangeably. Most likely, you have used web crawling and web scraping interchangeably because why not?
You probably think they mean the same thing since they sound very similar. Yes, they sound alike, but web crawling and web scraping are distinct processes. If you often mix them up, then this article is for you.
But, “are they not the same? They sound quite alike,” you are probably wondering.
This guide will examine the differences between web crawling and web scraping with regard to their definition, how they work, use cases, benefits, limitations, and how to optimize their efficiency with NetNut.
Web crawling vs Web scraping: Definition
Web crawling is the process whereby web crawlers or spiders read and store the content on a website for indexing purposes. Search engines such as Google use web crawlers to identify and retrieve all the information on a website and index it in its archive. Google needs to index web pages to easily tell you which web page has the specific information you need.
However, some websites have indexing issues, which prevent web crawlers from accessing their pages. If you are reading this, you probably have web pages- you can check their index status on the Google index coverage report. Consequently, you can identify the issues and fix them.
On the other hand, web scraping can be defined as extracting data from a specific website by a web scraper. Web scraping can be done manually, but it is time and resource-intensive.
Nowadays, web scraping (bots) are used to collect data from a web page. They can parse the HTML content of the web page and extract the data as text or table. For example, you can extract data from a web page into a Google Excel Spreadsheet.
Web crawling aims to understand the content of a website. In contrast, web scraping aims to convert targeted website data (usually in unstructured format) into structured formats such as JSON, XML, and tables.
Web crawling vs Web scraping: How they work
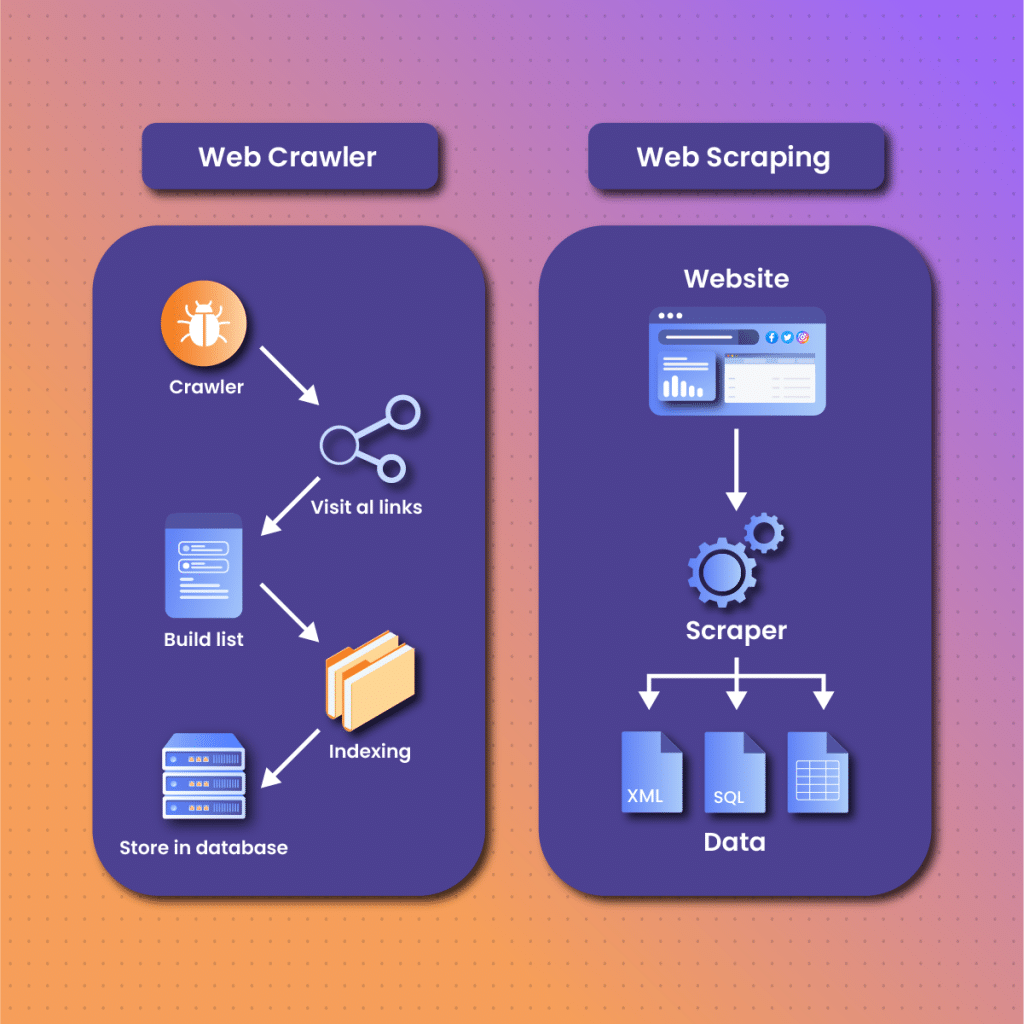
Now that we understand the direction of web crawling vs. web scraping let us move on to another significant aspect- how they work.
Web crawling and web scraping have various processes. So, let us examine these processes to provide a better understanding.
Web Crawling
Web crawling fetches URLs and parses them to make access to specific URL components easier. The bot collects and reviews all pages corresponding to the URL and then indexes all the available information, which is then archived in a database.
Every website is a collection of web pages with specific domain names hosted on a server. Each page is built from HTML and HTML structures, including CSS elements, JavaScript code, HTML tags, and the website meta-data such as keywords and meta-description.
Search engines understand the structure of websites, so they customize web crawlers to focus on specific attributes and crawl web pages accordingly. The URL seed serves as the starting point, which will later generate new URLs for the web crawler to parse.
In essence, the crawler needs two lists for indexing- one for the URL it has visited and another for those it will visit. The web crawler uses the queue data structure to maintain order on the lists.
Web scraping
Web scraping begins with identifying a target website containing the data you want to extract. Typically, web scraping allows you to send a request to the website. However, you should consider using proxies due to anti-scraping techniques like CAPTCHAs, which could lead to IP blocks. They assign your device a different IP address to hide your real identity. Consequently, it optimizes the process of extracting data from websites.
Once you enter the website’s address in the web scraper, it returns data to your computer in the form of text, CSV, JSON, or others.
A web scraper has three primary constituents. First, a web crawling code that allows it to send a request to the website. The second is a function for parsing and collecting data; the third component is a function for saving and exporting extracted data.
Web crawling vs Web scraping: Use cases
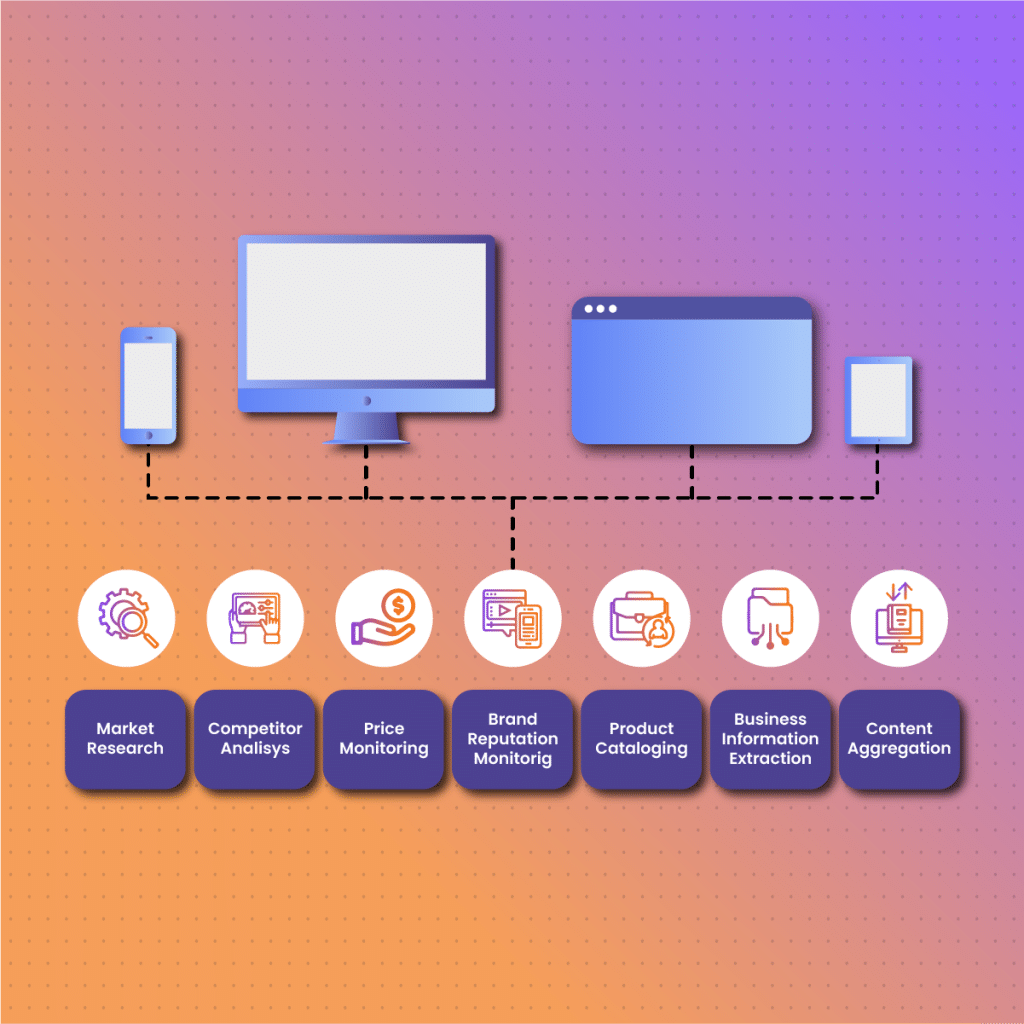
Web crawling and web scraping have distinct applications.
Search engines like Yahoo and Google use web crawling to display pages and relevant information. Search Engine Optimization (SEO) is a technique that helps websites rank on search engine result pages. The web crawler is a tool that search engines utilize to assess a website’s position and index information to optimize customer experience.
For example, if you search “Vegan food” on Google, it scours the internet and returns web pages that rank on the search engine search. These websites are optimized; they contain keywords in the right density, meta-description, meta-tags, and others.
Here are some applications of web crawling:
Website indexing
This is the most common application of web crawlers. Search engines use web crawling to map and index web pages based on relevance. Web crawling was a solution to the “back-of-the-book indexing,” which was slow and unreliable.
It indexed websites by arranging them alphabetically or through the traditional sorting mechanisms. However, search engines started producing better results by using meta tags, including keywords.
Website maintenance
Web crawling plays a significant role in website maintenance. Instead of manually checking for errors or inconsistencies, the admin can use web crawling to automate the website’s maintenance process.
For example, if there is a broken link on a website, maybe the link to the testimonial page. The web crawler will alert the admin, who fixes the issue to ensure it is functional.
Data collection
Data collection is an application of web crawling. Almost all web scraping uses web crawlers, but web crawling rarely needs web scrapers. The first step in web scraping is finding the right website which is only possible with web crawling. As a result, scrapers are built with a module that can crawl web pages, which makes it easier to find relevant pages.
Host and service freshness check
Almost all web pages rely on external hosts and services. However, these external servers may experience some downtime, which may affect a website’s functionality.
Web crawlers can access freshness, which determines the uptime of external hosts. This freshness index is calculated using the freshness threshold. Therefore, a web crawler can periodically ping each external host and compare them to the freshness threshold. As a result, the admin can easily determine which external service provider is fresh or stale.
Applications of web crawling
On the other hand, web scraping allows businesses to access critical data from one or various web pages. Some of the use cases include:
- Research: Data is fundamental for any research, whether in academics, medicine, or business. The ability to collect user data in real-time helps to identify trends and patterns that can inform critical decisions.
- Brand protection: Brand protection is becoming increasingly critical as internet fraud is on a steady rise. Therefore, businesses rely on data collection to monitor brands as well as identify and take legal actions against any criminal.
- Ecommerce: Although ecommerce was on a steady rise, the Covid-19 pandemic caused an explosion as many businesses had to leverage the internet for sales. Competition is fierce in the ecommerce industry. Therefore, data collection becomes critical to access data and monitor consumer sentiment to get a competitive edge.
- Strategy development: To develop a strategy that works, you need data. Web scraping exposes you to data that allows you to identify industry trends and SEO practices.
- Product development: Web scraping allows ecommerce businesses to find out the performance of their products. In addition, they can collect data on customer reviews that guide product development.
- Lead generation: Another critical application of web scraping is lead generation. Leads are critical for businesses, especially new ones. It may be challenging to get leads without customer data. Web scraping can streamline the lead generation process by collecting customer data from websites, including name, email, or phone number.
Web crawling vs Web scraping: Advantages and limitations
Web crawling and web scraping are two important processes for gathering data. However, they have unique pros and cons, which we will examine below.
Benefits of web crawling
- Efficient for web indexing: Web crawling is an efficient method for web indexing, making retrieving information on the internet easy.
- Increases site traffic: Since web crawlers can be configured to maintain websites automatically, it can increase their traffic. It identifies issues that may affect search engine ranking on the result page.
- Excellent tracking system: As web crawlers have an excellent tracking system, they become crucial to keeping track of information such as user activity.
- Less privacy concerns: Web crawlers do not download targeted data from websites. Therefore, there are limited concerns about its action on websites.
- It does not require large storage: Web crawlers do not extract data from various websites. Therefore, it is an excellent choice when large storage is a challenge.
Limitations of web crawling
- It has limited application as it is primarily for website maintenance and indexing
- Crawling each web page may consume excessive server bandwidth
- Web crawlers are vulnerable to anti-scraping techniques, including IP bans
- Web crawling may be inefficient if meta-data is incorrect
Pros of Web Scraping
- Versatility: Web scraping allows the extraction and storing of data from any website across the globe.
- Fast: Automated web scraping can download large volumes of data at a fast pace. This optimizes the process of collecting data from various web pages across the internet.
- It is not limited to meta-data: Unlike web crawling, the efficiency of web scrapers is not reliant on the accuracy of the meta-data.
- Selective: Depending on the command in the source code, web crawlers focus only on relevant web pages. As a result, they do not parse every website on the internet, which optimizes the process.
Limitations of Web Scraping
- Although web scraping is legal, it is often perceived as unethical. Therefore, this raises a lot of controversies regarding its application.
- Websites with anti-scraping techniques can identify and block web crawlers, which poses a significant challenge to the efficiency of web data retrieval.
- Developers may need to create a program that mimics human behaviors so that web crawling activities will not be detected as bots.
Web crawling vs web scraping: Common challenges
Web crawling and web scraping are similar because they require an automated tool. Therefore, they share some common challenges, which we shall examine.
IP blocking
Many websites have measures to identify and block web scraping or crawling bots. As a result, it becomes challenging to collect data. Sometimes, you may already be scraping the data from a website when the mechanism is triggered, and your IP address is blocked. Consequently, you are robbed of real-time data collection.
Resource intensive
When performed at a large scale, web crawling and web scraping can be resource-intensive and time-consuming. Therefore, the need to automate these processes becomes a priority. However, the efficiency of a large volume of data may depend on the versatility of its programming language.
Spider trap
Spider trap is designed to mislead web crawlers, which causes it to fetch malicious pages, including spam URLs, instead of actual websites. This triggers an infinite loop where the malicious pages dynamically generate spam links and redirect crawlers to this link so it gets stuck within the spam web pages.
Robots.txt
Robots.txt is a file that specifies what web pages can be crawled and those off-limits. Therefore, before you put any website address into your crawler, review this file to understand the constraints. This will influence how you customize your crawling codes to prevent being permanently kicked out of the website.
How to optimize your web crawling and web scraping- Netnut
One of the best practices when using crawlers is the use of proxies. Netnut is a global solution that provides various proxies to cater to your specific data extraction needs. These proxies serve as intermediaries between your device and the website that holds the data.
NetNut rotating residential proxies are your automated proxy solution that ensures you can access websites despite geographic restrictions. Therefore, you get access to real-time data from all over the world that optimizes decision-making.
In addition, you can use our in-house solution- NetNut Scraper API, to access websites and collect data. Moreover, if you need customized web scraping solutions, you can use NetNut’s Mobile Proxy.
Netnut has an extensive network of over 52 million rotating residential proxies in 195 countries and over 250,000 mobile IPS in over 100 countries, which helps them provide exceptional data collection services.
The various proxy solutions are designed to help you overcome the challenges of web scraping for effortless results. These solutions are critical to remain anonymous and prevent being blocked while scraping data from web pages.
Conclusion
This guide has examined web crawling vs web scraping in terms of definition, how they work, pros, cons, similar challenges, and how to overcome them.
As a recap, web crawling aims to find new web pages, and automated crawling bots perform it. On the other hand, web scraping aims to collect specific data by parsing HTML content and storing the data in JSON, Spreadsheet, CSV, and other formats.
We can see from the application of web crawling vs web scraping that they are quite distinct, even though they are often misused. Regardless of the type of bot you are using, it is highly recommended to use Proxy solutions to optimize crawling and scraping activities.
Do you want to experience an industry-leading proxy solution? Kindly reach out to Netnut today to get started!
Frequently Asked Questions
Web crawling vs web scraping: what’s the difference?
The primary difference between web crawling and web scraping is their activities. Web crawling involves discovering links on the web, while web scraping involves collecting data from websites.
Is web scraping the same as data scraping?
Web scraping and data scraping are also used interchangeably. However, there is a significant difference between them. Web scraping is the extraction of specific data from one or more websites. On the other hand, data scraping is collecting data from any source, whether in PDF, text, multimedia file, or spreadsheet.
Web crawling vs web scraping: what are the types?
Types of web crawlers include:
- General-purpose web crawlers often require a strong internet connection and vast memory
- Focused web crawlers, which are optimized for specific tasks
- Parallel web crawler- runs one or more web crawling processes in parallel
- Incremental web crawler – helps to track frequently changing web content like news
- Deep web crawler- uses specific keywords to access the deep web
Types of web scrapers
- Manual scraper
- HTML parser
- DOM parser
- Vertical aggregators






