The internet is a vast ocean of information, with data on everything, from the latest product trends to obscure historical and other forms of data you may think of. But how do you grab all that valuable data and turn it into useful insights? That’s where web scraping use cases come in.
Today, we’ll explore the various web scraping use cases. We’ll explore how businesses, researchers, and individuals can use this technology to gain a competitive edge, conduct groundbreaking research, and make informed decisions in a data-driven world.
Keep reading because you are a step away from discovering web scraping use cases and how you can use this knowledge for your benefit.
Web Scraping Use Cases: What Is Web Scraping?
Web scraping is a technique that involves using automated tools like BeautifulSoup (in Python), Scrapy, and Selenium to extract data from websites. These tools act as robots, and they help you gather information by searching through web pages and pulling out specific details. They do it much faster and more efficiently than a human copying and pasting content. However, some processes are required for these tools to carry out your command effectively. This process involves sending requests to a website, parsing the HTML, and grabbing the desired data. Furthermore, web scraping use cases are vast, from data analysis to price comparison, but it is essential to be mindful of ethical considerations and follow website terms of service. Additionally, as we proceed in our discussion on web scraping use cases, these ethical considerations will be made clear.
Web Scraping Use Cases: Benefits Of Web Scraping
Web scraping use cases offers several benefits, including:
It Improves Decision-Making
Businesses several web scraping use cases empower them to make informed decisions based on up-to-date and comprehensive data. This enhances strategic planning and execution of the plans.
It Enhances Product Development
Web scraping use cases support product development. This is a result of analyzing customer reviews and preferences by these companies, enabling them to tailor their services to meet market demands.
It Helps In Market Trends Identification
One of the vital aspects of web scraping use cases is that it helps businesses identify emerging market trends and customer behavior patterns through continuous monitoring of data changes on various platforms.
It Enables Efficient Resource Allocation
One benefit of indulging in several web scraping use cases is that it optimizes resource allocation. This occurs by streamlining data-gathering processes, which allow the teams to focus on higher-value tasks rather than manual information retrieval.
It Facilitates Strategic Pricing
Web scraping use cases in finance facilitate different pricing strategies by businesses. This is possible through analyzing competitors’ pricing trends and adjusting pricing models accordingly by these businesses to stay competitive in the market.
It Supports Supply Chain Optimization
Web scraping use cases support supply chain management by monitoring and analyzing supplier data. This ensures a streamlined and cost-effective supply network.
It Allows Brand Monitoring
The several web scraping use cases allow businesses to monitor several online activities like mentions, reviews, and critics around their brand. This enables them to take proactive reputation management.
It Assist In Regulatory Compliance
Web scraping use cases assist businesses in monitoring regulatory changes and compliance requirements within specific industries. This enables them to stay up-to-date with legal standards.
It Enables Data Extraction
Web scraping use cases enable automated data extraction from websites, saving time and effort in manual data collection. However, you can use a proxy to carry out your web scraping task efficiently. Proxy types such as ISP and mobile proxies can help in geo-restrictions and blocking, allowing you to scrape with ease.
Web Scraping Use Cases: The Importance Of Ethical Scraping Practices.
When discussing web scraping use cases, how you scrape data is paramount in maintaining integrity. This is called “ethical scraping practice”. Adhering to ethical guidelines ensures respect for the rights and policies of website owners, and it promotes responsible data use. Ethical scraping involves obtaining data with the explicit consent of the website, respecting terms of service, and avoiding actions that could harm the site’s functionality or compromise user privacy. Additionally, businesses and individuals can contribute to a sustainable and collaborative online environment by prioritizing ethical considerations. This practice is essential in web scraping use cases to enhance web development.
Web Scraping Use Cases: Consequences Of Unethical Web Scraping
When learning web scraping use cases, it is essential to know the consequences of unethical web scraping so as not to fall victim to it by any chance. These consequences include:
Legal Action May Be Taken
In addition to cease and desist orders, fines, and lawsuits, legal consequences of unethical web scraping use cases can extend to criminal charges, especially if the violation involves intentional data theft, fraud, or unauthorized access to sensitive information. Also, businesses engaged in unethical web scraping use cases may be surrounded by legal battles, incurring substantial legal fees and potential financial damages.
It May Lead To Reputational Damage
The fallout from reputational damage can be extensive. Adverse publicity resulting from unethical web scraping use cases may lead to customer loyalty and trust loss. More so, a series of ill reports such as social media backlash, negative reviews, and public condemnation resulting from unethical web scraping use cases can harm a company’s standing within its industry, making it challenging to rebuild trust and regain a positive image.
It Can Result In Intellectual Property Claims
When engaging in unethical web scraping use cases that involve unauthorized use of intellectual property, trademarks, or proprietary information can lead to intellectual property claims. This can result in legal complications such as injunctions, royalties, or the forced removal of content derived from scraped data.
It Can Cause Damage To Relationships With Data Sources
If the data to be scraped is owned or provided by external sources, engaging in unethical web scraping use cases can strain relationships with these sources. This can lead to withholding valuable data, refusal to share updates or even legal action from these data providers.
It May Lead To Ip Blocking
Implementing IP blocking is a common defense mechanism against unethical web scraping use cases. Websites can detect abnormal traffic patterns indicative of unethical web scraping use cases and block the associated IP addresses. This can thwart current scraping attempts. However, overcoming IP blocking can require a proxy server, such as rotating proxies.
It Can Cause Damage To SEO Ranking
Engaging in unethical web scraping use cases, particularly aggressive crawling that puts excessive strain on a website’s servers, can negatively impact performance and load times. Search engines consider user experience necessary, and a website’s SEO ranking may suffer due to prolonged loading times caused by scraping activities. This can lower SEO rankings and hinder the website’s overall visibility in search engine results.
It Leads To Devaluation Of Scraped Data
Even if successfully obtained, data acquired through unethical web scraping use cases may be viewed skeptically by users, customers, and industry peers. The tainted reputation of the scraping entity can cast doubt on the accuracy and reliability of the scraped data, diminishing its value for decision-making and analysis.
It Can Cause Heightened Security Measures By Websites
Unethical web scraping use cases may trigger heightened security measures on websites, leading to additional costs for implementing security protocols. However, as a way out, websites can invest in technologies like web application firewalls (WAFs) and bot detection systems to add a layer of defense against future unethical web scraping use cases.
It May Result In Industry Blocklisting
Engaging in unethical web scraping use cases can lead to industry blocklisting. This can cause a scraper to be identified as a threat or bad actor within a specific sector. The consequence can be restricted access to industry-related websites, databases, or collaborative platforms. However, being blocklisted limits collaboration opportunities, partnerships, and access to critical industry information, hindering a business’s growth and potential for innovation.
Web Scraping Use Cases: Business & Marketing
As one of the critical web scraping use cases, let’s explore the various ways scraping is used in the business and marketing sector. It includes:
Lead Generation
Business and marketing web scraping use cases streamline lead generation by extracting contact details from online directories, social media platforms, and other public sources. Businesses can build targeted and comprehensive lead lists. This can enhance their outreach efforts and increase the efficiency of their sales.
Market Research
Web scraping use cases in the business and marketing sector help collect data on competitors, conduct product research, and analyze customer critics. By aggregating and analyzing this information, businesses can gain insights into market trends, consumer preferences, and areas for potential innovation.
Content Aggregation
Web scraping use cases in the business and marketing sector facilitate content aggregation by pulling relevant information from various sources, including news websites, blogs, and social media. This information can be used to create engaging blog posts, newsletters, and social media updates, saving time and effort in content creation.
Competitive Intelligence
Web scraping use cases in the business and marketing sector help monitor industry trends and stay informed about competitors. This enables businesses to gather competitive intelligence and analyze data related to effective marketing strategies.
Web Scraping Use Cases: Finance & Investments
Web scraping use cases in the finance sector are noteworthy, and they include the following:
Financial Data Analysis
Web scraping use cases in the finance sector help efficiently collect a large amount of financial data. This includes scraping stock prices, company financial reports, economic indicators, and currency exchange rates. However, accessing historical and real-time financial data enables analysts and investors to perform in-depth analyses, make informed investment decisions, and create predictive models for market trends.
Sentiment Analysis
Web scraping use cases in the finance sector helps monitor critics to make well-informed investment decisions. Performing sentiment analysis is possible by gathering data from various sources, such as news articles, financial blogs, and social media platforms.
Real Estate Data
Web scraping use cases in the finance sector help collect and analyze real estate data. This is achievable through scraping property listings, rental prices, and market trends from real estate websites. Investors, real estate agents, and analysts use this data to identify investment opportunities, understand market dynamics, and track changes in property values. Additionally, web scraping use cases in the finance sector aid in conducting comparative market analysis and predicting future trends
Web Scraping Use Cases: Research & Development
Web scraping use cases in the research and development sector are vital, and use cases include:
Academic Research
Web scraping use cases in the research & development sector help collect data for various academic research projects, scientific studies, and surveys. This enables researchers to gather relevant information from websites, forums, and databases, facilitating knowledge extraction in diverse fields.
Machine Learning Training
Web scraping use cases in the research and development sector help acquire large and diverse datasets for training machine learning models. By extracting relevant data from the web, researchers and developers can create accurate models that enhance the capabilities of machine learning algorithms in tasks such as image recognition, natural language processing, and sentiment analysis.
Data Journalism
Web scraping use cases in the research and development sector are employed for data-driven storytelling and investigative reporting in journalism. This approach enhances the depth and accuracy of reporting, providing readers with a comprehensive understanding of complex issues.
Web Scraping Use Cases: Travel & Tourism
Web scraping use cases in the travel industry involve extracting valuable information such as travel deals, flight prices, and hotel reviews from various websites. This data enables businesses and consumers to compare prices, plan itineraries, and make informed decisions. Again, scraping travel-related content helps stay competitive, adjust pricing strategies, and provide users with relevant information for their travel plans.
Web Scraping Use Cases: E-commerce
In the e-commerce sector, web scraping use cases extract product data for various purposes. Businesses use scraping to gather information for price comparison, monitor competitor prices, and analyze product trends. Also, consumers can benefit from Web scraping use cases in the e-commerce sector by conducting thorough product research, comparing prices across different platforms, and making informed purchasing decisions.
Web Scraping Use Cases: Job Searching
Web scraping use cases in job searching help aggregate job postings from diverse sources. This provides job seekers with a consolidated view of available opportunities. By extracting data from job boards, company websites, and other employment platforms, individuals can streamline their job search, access a broader range of opportunities, and stay updated on the latest job postings in their desired fields.
Web Scraping Use Cases: Web Development
Web scraping use cases in web development can propagate web design inspiration and obtain data for analysis. This helps developers stay informed about the latest industry standards, enhance their skills, and create more innovative and user-friendly websites and applications.
Web Scraping Use Cases: Introduction To Different Web Scraping Tools And Libraries.
Web scraping tools and libraries are essential for efficiently extracting data from websites. Here’s an introduction to some popular ones:
Beautiful Soup
Beautiful Soup uses Python as its language. It is primarily used for pulling data out of HTML and XML files. This creates a parse tree from page source code, making navigating and searching for specific elements easy.
Scrapy
Scrapy is an open-source and collaborative web crawling framework using Python. It provides a complete toolset for extracting, processing, and storing data in preferred formats.
Selenium
Selenium is primarily used for automating web applications by simulating human interaction. However, it uses several programming languages and helps scrape dynamic content rendered through JavaScript.
Requests-HTML
Requests-HTML is a Python library that simplifies extracting information from websites by combining requests and pyquery to provide an easy-to-use API for web scraping.
Puppeteer
Puppeteer is a Google-developed headless browser automation tool for web scraping and automated testing. It enhances interaction with pages and handles dynamic content quickly. Also, it uses JavaScript (Node.js)
Octoparse
Octoparse is a visual scraping tool that allows users to point and click to create extraction rules. It is suitable for those without extensive programming skills. This library uses GUI-based (no coding required) Language.
Web Scraping Use Cases: Factors To Consider When Choosing A Scraping Tool
Choosing the right web scraping tool is very important for the success of your project. Consider the following factors when selecting a scraping tool:
Ease Of Use
You must evaluate the tool’s user interface, documentation, and learning curve. A tool with a user-friendly interface and clear documentation can streamline the scraping process, especially for beginners.
Scalability
You need to check if the tool you want to use can handle the scale of your scraping project. Some tools are better suited for small-scale tasks, while others are designed to handle large and complex scraping operations.
Support For Dynamic Content
If the websites you’re scraping use dynamic content loaded through JavaScript, you can choose a tool that supports dynamic rendering or integrates well with servers like Proxies or even libraries like Selenium, Beautiful Soup, etc.
Community And Support
You need to check the community support and online forums associated with the scraping tool. A vibrant community often indicates active development, ongoing support, and a wealth of resources for problem-solving.
Robustness And Reliability
Another consideration you need is to check the tool’s stability and reliability in handling different types of websites. A good scraping tool should be resilient to changes in website structures and consistently provide accurate results.
Customization And Flexibility
Also, you need to consider the level of customization the tool allows. Some scraping tools offer high flexibility, allowing users to tailor their scraping logic to specific website structures and requirements.
Data Export And Integration
Try to check the tool’s capabilities for exporting scraped data. Choose a tool that supports common data formats (CSV, JSON, etc.) and integrates well with other tools or databases you might use.
Proxy Support
If scraping multiple websites or dealing with IP blocking concerns, ensure the tool supports proxies. Proxies like residential proxies and static residential proxies can help distribute requests, prevent IP bans, and enhance anonymity.
Legal And Ethical Compliance
Be aware of the tool’s compliance with legal and ethical standards. Some tools may have built-in features to regulate scraping speed, respect website terms of service, and avoid legal issues.
Cost And Budget
You need to evaluate the cost structure of the scraping tool, considering both initial investment and ongoing costs. Some tools may be open-source or have free plans, while others may require a subscription or one-time payment.
Updates And Maintenance
You need to choose a regularly updated and maintained tool by its developers. This ensures compatibility with website changes and may introduce new features or improvements.
Web Scraping Use Cases: Best Practices For Responsible And Ethical Scraping
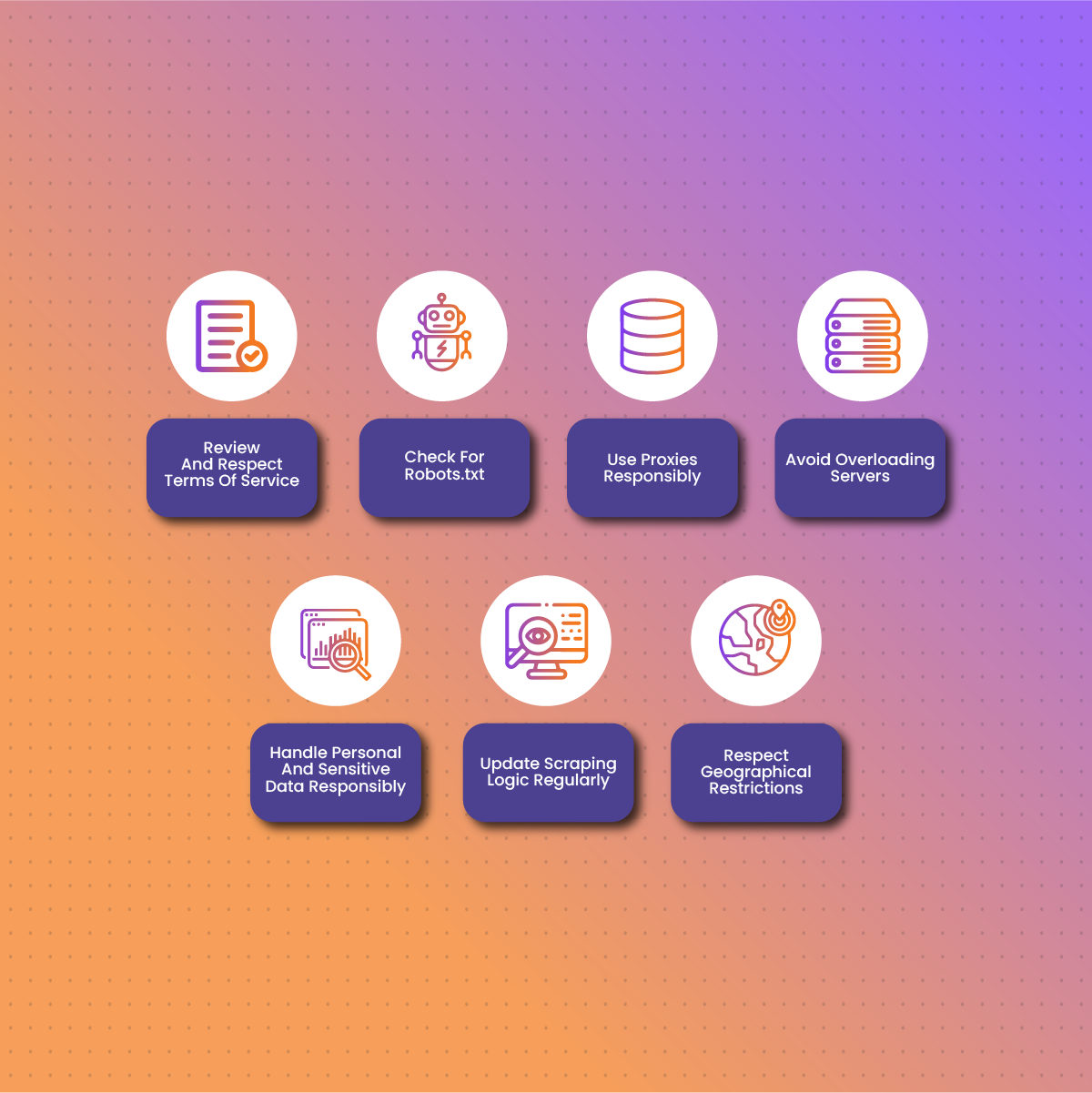
Responsible and ethical web scraping use cases are essential to maintaining a favorable online ecosystem and adhering to legal standards. Here are some considerations:
Review And Respect Terms Of Service
Always read and adhere to the terms of service of the websites you are scraping. Also, you need to respect the rules and guidelines set by the website owners.
Check For Robots.txt
Before scraping, you need to check the website’s `robots.txt` file to understand any restrictions or guidelines set by the website for web crawlers. Avoid scraping disallowed content.
Use Proxies Responsibly
If employing proxies, ensure they are used ethically and legally. You must respect the proxy provider’s terms of service and adhere to website restrictions regarding IP addresses.
Avoid Overloading Servers
Be mindful of the server load your scraping activity generates. Excessive requests can lead to server overload, affecting both the website’s performance and your scraping efficiency.
Handle Personal And Sensitive Data Responsibly
If your scraping involves personal or sensitive information, handle it carefully. Ensure compliance with data protection laws and respect user privacy rights.
Update Scraping Logic Regularly
Regularly update your scraping logic to adapt to website structure changes. This helps maintain the accuracy of your data extraction and avoids unnecessary disruptions.
Respect Geographical Restrictions
If a website has geographical restrictions, respect them. Avoid attempting to scrape data from regions where you are not permitted.
Web Scraping Use Cases: Frequently Asked Questions
What Are Common Use Cases For Web Scraping In Business?
Web scraping finds extensive applications in various business domains. Here are some critical instances:
Lead Generation
Business and marketing web scraping use cases streamline lead generation by extracting contact details from online directories, social media platforms, and other public sources. This can enhance their outreach efforts and increase the efficiency of their sales.
Market Research
Web scraping use cases in the business and marketing sector help collect data on competitors, conduct product research, and analyze customer critics. By aggregating and analyzing this information, businesses can gain insights into market trends, consumer preferences, and areas for potential innovation.
Content Aggregation
Web scraping use cases in the business and marketing sector facilitate content aggregation by pulling relevant information from various sources, including news websites, blogs, and social media. This information can be used to create engaging blog posts, newsletters, and social media updates, saving time and effort in content creation.
What Are Common Use Cases For Web Scraping In Job Searching?
Web scraping use cases in job searching help aggregate job postings from diverse sources. This provides job seekers with a consolidated view of available opportunities. By extracting data from job boards, company websites, and other employment platforms, individuals can streamline their job search, access a broader range of opportunities, and stay updated on the latest job postings in their desired fields.
Is Web Scraping Legal, And What Ethical Considerations Should Be Taken Into Account?
Web scraping is generally legal, but ethical considerations are essential. Always adhere to website terms of service, respect robots.txt files, and avoid aggressive scraping that could disrupt a website’s functionality. Handling personal or sensitive data responsibly, using proxies ethically, and being transparent about scraping activities contribute to ethical web scraping practices.
Web Scraping Use Cases: Conclusion
As we reach the end of our web scraping use cases exploration, it’s clear that this technology is advanced with many benefits. It can change how we gather information, make decisions, and, ultimately, explore the internet. However, for effective web scraping, you need a proxy server. That’s where NetNut comes in. We offer all proxy types, including datacenter proxies, and our services ensure all traffic is routed exclusively through the NetNut network; no third-party computers are utilized. As a result, there won’t be any disconnections or interruptions in your proxy network. So, what are you waiting for? Check out our blog for any information or inquiries, and integrate with us today.