Introduction
In case you are looking for an efficient way to get data online related to traveling, web scraping is your go-to option. Meanwhile, TripAdvisor is arguably the world’s largest travel platform; whether you’re planning a dream vacation, or looking for the perfect place to stay, TripAdvisor has got you covered. Therefore this guide will focus on how scraping TripAdvisor works.
Why scrape TripAdvisor data, you might wonder? TripAdvisor data empowers you to make strategic and informed decisions. Subsequently, by accessing and analyzing the information available on TripAdvisor, businesses can gain valuable insights into consumer preferences, market trends, and competitor performance.
In this article we’ll walk through the step-by-step process of scraping TripAdvisor data. This will include identifying your target information to storing the scraped data for analysis.
What is web scraping?
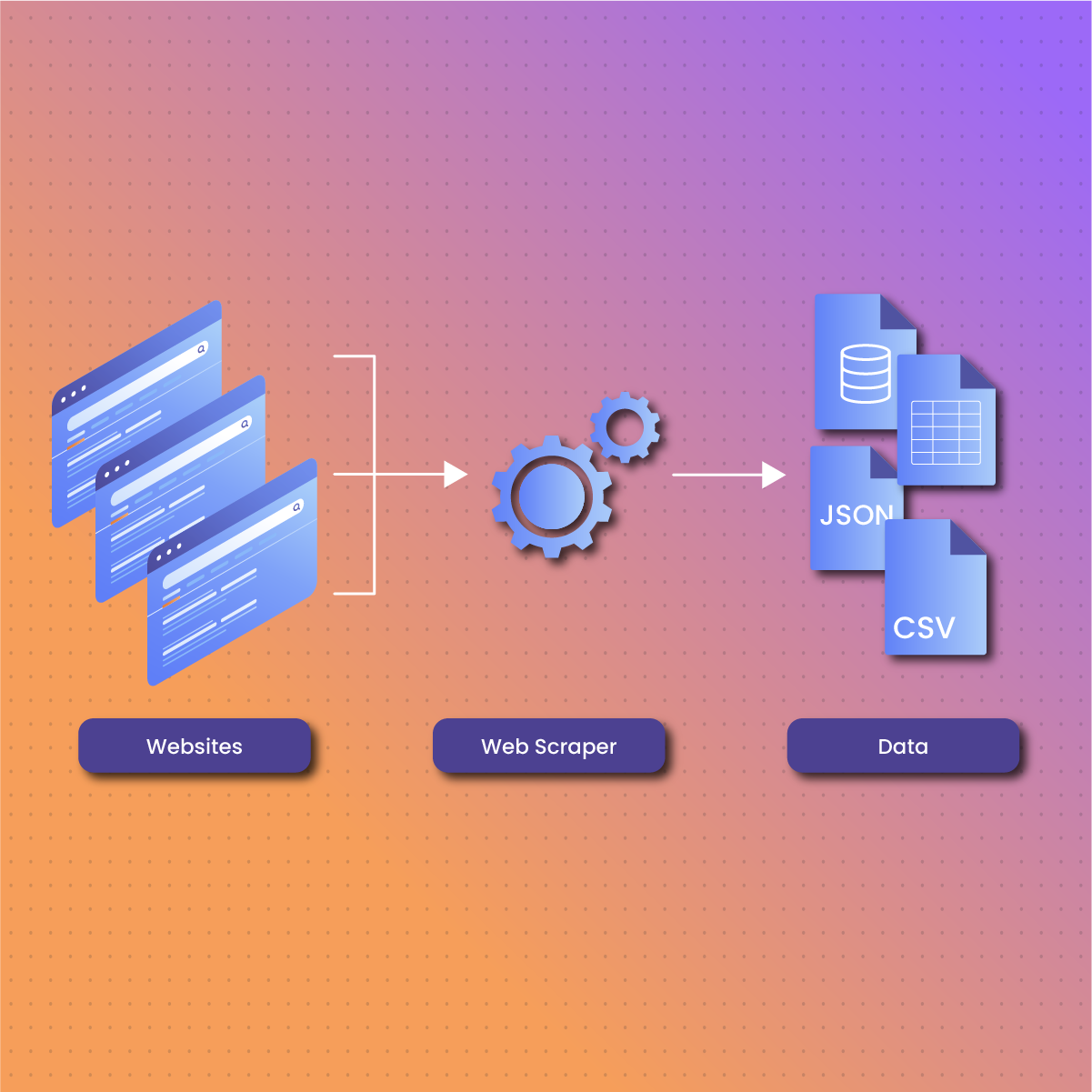
Web scraping is the process of extracting data from websites. It involves parsing the HTML or XML code of a web page to extract the desired information, such as text, images, or links. While web scraping can offer numerous benefits, it’s essential to approach it responsibly and ethically to avoid violating website terms of service or infringing on privacy rights.
Key tools and techniques for web scraping
Web scraping, the process of extracting data from websites like TripAdvisor, has become increasingly popular due to its ability to gather valuable information for various purposes. Below are some key tools and techniques commonly used in web scraping:
BeautifulSoup
BeautifulSoup is a Python library that makes it easy to scrape information from HTML and XML files. It provides methods for navigating the HTML structure of a webpage, extracting specific elements based on tags, attributes, or classes, and manipulating the parsed data. BeautifulSoup simplifies the process of extracting data by providing a simple and intuitive interface.
Requests
The requests library is used in Python for sending HTTP requests to web servers. It allows developers to retrieve HTML content from webpages, making it an essential tool for web scraping. With requests, developers can send GET and POST requests, handle cookies and sessions, and customize request headers. This library is often used in conjunction with BeautifulSoup to fetch HTML content for parsing.
Scrapy
Scrapy is a powerful and extensible framework for scraping and crawling websites. It provides a high-level API for extracting data from webpages, handling pagination and dynamic content, and storing scraped data in various formats. Scrapy is particularly useful for building large-scale web scraping projects, as it offers features such as automatic throttling, parallel processing, and built-in support for handling robots.txt and user-agent headers.
Selenium
Selenium is a browser automation tool commonly used for testing web applications, but it can also be utilized for web scraping tasks. Selenium headless browser allows developers to control web browsers programmatically. This enables interactions with dynamic content, JavaScript execution, and form submissions. It is particularly useful for scraping websites with complex JavaScript-driven user interfaces that cannot be easily parsed using traditional scraping techniques.
XPath and CSS selectors
XPath and CSS selectors are powerful querying languages used to navigate and select elements within an HTML document. XPath is a syntax for defining paths to elements in an XML or HTML document, while CSS selectors are patterns used to select elements based on their attributes, classes, or positions in the document tree. These selectors are often used in conjunction with BeautifulSoup or Scrapy to extract specific elements from webpages accurately and efficiently.
User-Agent rotation
Many websites implement rate limiting or block IP addresses that send too many requests in a short period. To overcome this limitation, developers can rotate User-Agent headers in their HTTP requests to simulate different web browsers or devices. This technique helps disguise scraping activities and avoid detection by websites’ anti-scraping measures.
Data cleaning and Parsing
Once data has been scraped from a website, it often requires cleaning and parsing to extract relevant information and remove noise. This may involve converting HTML content to structured data formats such as JSON or CSV, removing HTML tags, handling encoding issues, and normalizing data formats. Data cleaning and parsing are essential steps in preparing scraped data for analysis or storage.
How to scrape TripAdvisor data using Python

Scraping data from TripAdvisor using Python can unlock numerous insights for businesses, researchers, and travelers alike. Whether you’re analyzing hotel reviews, monitoring restaurant ratings, or studying travel trends, Python provides powerful tools and libraries to automate the process of gathering data from TripAdvisor’s website.
Python offers several libraries for web scraping, including BeautifulSoup, requests, and Scrapy. This streamlines the process and makes it accessible to developers of all skill levels. The process of web scraping TripAdvisor with Python script involves:
Choosing the right tools
To scrape TripAdvisor data effectively, we’ll primarily use two Python libraries: BeautifulSoup for parsing HTML content and requests for sending HTTP requests. BeautifulSoup provides a convenient way to navigate and extract data from HTML documents. While requests simplifies the process of sending GET and POST requests to web servers.
Additionally, depending on the complexity of the scraping task, you may also consider using other libraries such as Selenium for interacting with dynamic web pages or Scrapy for building more complex scraping pipelines.
Identify target data
Before writing any code, it’s essential to identify the specific data you want to scrape from TripAdvisor. Whether it is hotel reviews, restaurant ratings, or attraction details. Therefore, having a clear understanding of your target data will guide your scraping process and help you design an efficient scraping strategy.
Writing the scraping script
Once you’ve identified your target data, it’s time to write the scraping script. Below is a basic example of how to scrape hotel reviews from a TripAdvisor page using BeautifulSoup and requests:
import requests
from bs4 import BeautifulSoup
def scrape_tripadvisor_reviews(url):
# Send a GET request to the TripAdvisor page
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, ‘html.parser’)
# Find the container that holds the reviews
reviews_container = soup.find(‘div’, class_=’review-container’)
# Extract the review text from each review container
reviews = [review.find(‘div’, class_=’entry’).get_text(strip=True) for review in reviews_container.find_all(‘div’, class_=’review-container’)]
return reviews
else:
print(“Failed to retrieve data from TripAdvisor”)
For better understanding of how the python script works, take note of these:
- We import the requests library for sending HTTP requests and the BeautifulSoup library for parsing HTML content.
- We define a function scrape_tripadvisor_reviews that takes a URL of a TripAdvisor page as input.
- Inside the function, we send a GET request to the provided URL, parse the HTML content using BeautifulSoup, and extract the review text from each review container.
- Finally, we return a list of review texts.
# Example usage:
url = ‘https://www.tripadvisor.com/Hotel_Review-g60763-d93511-Reviews-New_York_Hilton_Midtown-New_York_City_New_York.html’
reviews = scrape_tripadvisor_reviews(url)
if reviews:
for i, review in enumerate(reviews, start=1):
print(f”Review {i}: {review}\n”)
else:
print(“No reviews found.”)
Handling content and pagination
TripAdvisor pages often contain dynamic content loaded via JavaScript, which requires special handling when scraping. In such cases, libraries like Selenium can be used to automate interactions with the page, allowing you to access dynamically loaded content. In addition, TripAdvisor pages may have multiple pages of reviews, requiring pagination logic to scrape all reviews. You can go through the pagination links and scrape each page’s reviews until all reviews have been retrieved.
In summary, scraping TripAdvisor data using Python libraries like BeautifulSoup and requests makes the entire process easier and faster.
Best Practices for Ethical Scraping
As much as web scraping is a powerful tool for gathering data, it must be conducted responsibly. Below are some best practices for ethical scraping:
Respect website policies
Respecting website policies is paramount when engaging in web scraping activities. Before scraping any website, review its terms of service and adhere to any specific guidelines regarding data extraction. More so, respect the website’s robots.txt file, which indicates which parts of the site are off-limits to web crawlers. By following these policies, you can ensure that your scraping activities are conducted ethically and within the bounds of legality.
Managing scraping frequency
Managing the frequency of your scraping requests is essential for maintaining a harmonious relationship with the website you’re scraping. Sending too many requests in a short period can overload the server and trigger rate limiting or IP blocking mechanisms. To avoid this, implement throttling techniques such as adding delays between requests or limiting the number of requests per minute. By spacing your scraping activity, you can minimize the risk of disrupting the website’s operations and ensure a smooth scraping process.
Handling CAPTCHA challenges
CAPTCHA challenges are a common obstacle encountered when scraping websites, including TripAdvisor. These challenges are designed with bot detection tools to distinguish between human users and automated bots. Hence, failing to address them can result in access restrictions. To handle CAPTCHA challenges effectively, consider implementing CAPTCHA solving services or incorporating manual intervention into your scraping script. By addressing CAPTCHA challenges promptly and appropriately, you can maintain uninterrupted access to the website and avoid disruptions to your scraping workflow.
Utilizing proxies or VPNs
Utilizing proxies or virtual private networks (VPNs) can help prevent the risk of IP blocking and enhance your scraping capabilities. Proxies allow you to route your scraping requests through different IP addresses, making it more difficult for websites to detect and block your activity. Similarly, VPNs provide a secure and anonymous connection to the internet, allowing you to scrape data without revealing your true IP address. By rotating IP addresses and utilizing proxies or VPNs, you can avoid detection and minimize the likelihood of being blocked by TripAdvisor or other websites.
By adhering to these best practices for ethical scraping, you can web scrape responsibly and minimize the risk of encountering legal or technical issues.
Scraping TripAdvisor data using NetNut
Data is more valuable than ever, especially in the travel industry. Platforms like TripAdvisor hold a treasure of information, from hotel reviews to restaurant ratings, making them prime targets for data extraction. However, scraping data from websites like TripAdvisor can be challenging due to measures like IP blocking and CAPTCHA challenges. This is where NetNut comes in.
NetNut is a game-changing proxy service that prioritizes smooth web scraping. Unlike traditional proxies, which often get blocked or flagged by websites like TripAdvisor, NetNut offers a reliable and high-performance solution for scraping data on a large scale. With NetNut, you can access TripAdvisor’s website easily, bypassing common obstacles like IP blocking and CAPTCHA challenges.
How NetNut works
NetNut operates a vast network of residential proxies, allowing you to route your scraping requests through real user devices worldwide. This means you can scrape TripAdvisor data as if you were a regular user, without raising any red flags. NetNut’s unique rotating residential proxies ensure that your activities remain undetected. Also, it helps in resolving CAPTCHA challenges.
Why you should scrape TripAdvisor data with NetNut Proxies

NetNut has so far provided measures to resolve issues with traditional proxies. Compared to other proxy providers, NetNut makes web scraping TripAdvisor easier by providing:
- Reliable Access: One of the most significant benefits of using NetNut proxies is reliable access to TripAdvisor’s data. Unlike traditional proxies that may get blocked or flagged by websites, NetNut’s mobile proxies offer a reliable connection. With NetNut, you can access TripAdvisor’s website without worrying about interruptions or access restrictions, ensuring a smooth scraping process.
- High Performance: NetNut Proxies boast a high-performance network of rotating and static residential IPs, allowing you to scrape TripAdvisor data at lightning speed. Whether you’re scraping a few pages or thousands, say goodbye to slow loading times and hello to efficient data extraction.
- Anonymity: Privacy matters a lot. Hence, with NetNut proxies, your activities remain anonymous. More so, it ensures that your identity and location are kept private.
- CAPTCHA solving: CAPTCHA challenges are a common obstacle encountered when scraping websites like TripAdvisor. With NetNut’s ISP proxies, you can say goodbye to CAPTCHA challenges for good. NetNut offers CAPTCHA solving capabilities, allowing you to bypass these challenges without interruptions.
- Easy Integration: Integrating NetNut proxies into your scraping workflow is a smooth process. With simple setup instructions and comprehensive documentation, you can get started with NetNut proxies in minutes. Whether you’re a seasoned web scraping pro or a beginner, NetNut’s user-friendly interface and helpful support team are there to guide you every step of the way.
- Cost-Effective: Scraping TripAdvisor data using NetNut Proxies is not only reliable and efficient but also cost-effective. NetNut offers flexible pricing plans to suit your scraping needs, whether you’re a small business or a large enterprise. With transparent pricing and no hidden fees, you can scrape TripAdvisor data without breaking the bank.
Conclusion
In summary, scraping data from TripAdvisor can provide valuable insights for businesses, researchers, and travelers alike. By following ethical scraping practices, respecting website policies, and considering the rights and privacy of users, we can harness the power of web scraping responsibly and ethically.
By following the steps outlined in this guide, you can harness the power of TripAdvisor data to inform business decisions, conduct research, or plan your next adventure. Remember to scrape responsibly, respecting the website’s policies and user privacy at all times.
With the right approach and tools at your disposal, scraping TripAdvisor data can open doors to valuable insights and opportunities. So, whether you’re a business owner, a researcher, or a curious traveler, embrace the world of web scraping and unlock the wealth of information waiting to be discovered on TripAdvisor. Happy scraping!
Frequently Asked Questions and Answers
Can I scrape TripAdvisor using automated bots?
While TripAdvisor’s terms of service prohibit automated access for data scraping, you can still scrape data responsibly by following ethical scraping practices and respecting website policies.
What are the risks of scraping TripAdvisor?
Risks associated with scraping TripAdvisor include potential legal issues for violating website terms of service, IP blocking or rate limiting by TripAdvisor’s servers, and ethical concerns regarding user privacy.
Can I monetize data scraped from TripAdvisor?
Monetizing scraped data from TripAdvisor may be subject to legal restrictions and ethical considerations. Ensure compliance with relevant laws and obtain consent if you plan to use scraped data for commercial purposes.






