Introduction
At its core, machine learning is a subset of artificial intelligence that empowers systems to learn and improve from experience without being explicitly programmed. This paradigm shift from rule-based programming to learning from data has unleashed unprecedented capabilities, allowing machines to recognize patterns, make predictions, and evolve with changing circumstances.
A machine learning data set serves as the educational material for these algorithms, containing the diverse examples and scenarios needed for effective learning. These data sets contain information about the problem at hand, providing the algorithm with the necessary context to make accurate predictions or classifications.
As machine learning data continues to advance, the demand for thorough creation and thoughtful utilization of data sets becomes increasingly critical. In the subsequent sections, we will look into the types of machine learning data set, the challenges associated with working with them, best practices for optimizing their use, and a reflection on their pivotal role in the future of artificial intelligence.

Types of Machine Learning Data Set
A machine learning data set comes in various types, each tailored to specific tasks and algorithms. Understanding these types is crucial for selecting the right data set for a particular machine learning project. Here are some common types of a machine learning data set:
Structured Machine Learning Data Set
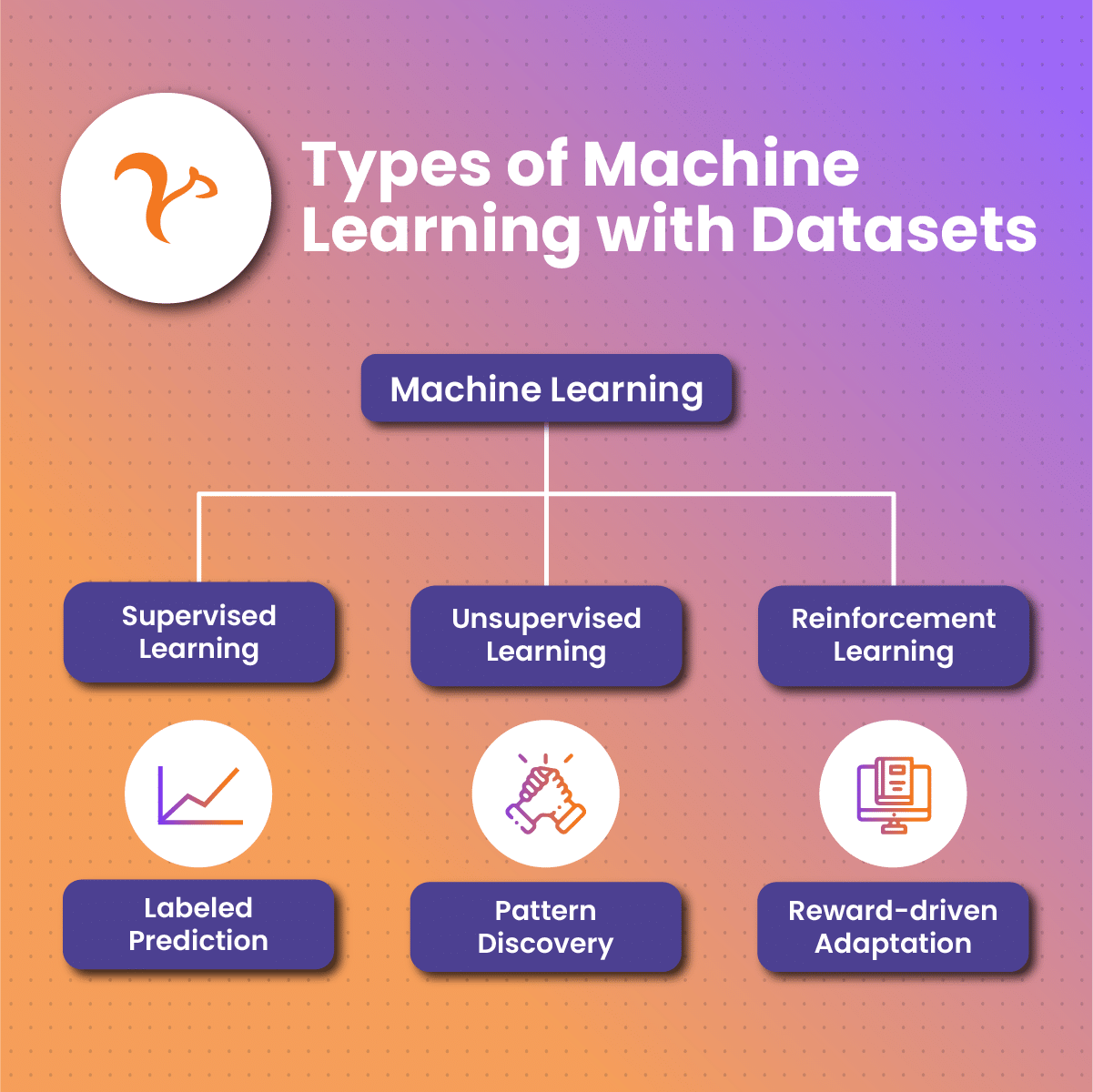
Structured machine learning data set is organized in a tabular format with well-defined rows and columns. Each column represents a specific attribute or feature, and each row corresponds to an individual data point. The structure allows for easy storage, retrieval, and analysis of the data. Characteristics include a clear organization, consistent format, and a direct mapping of features to columns.
- Examples: Databases, spreadsheets, CSV files.
- Use Cases: Structured machine learning data set is well-suited for supervised machine learning algorithms, where the algorithm learns from input-output pairs. Common applications include classification tasks, regression analysis, and data mining.
Unstructured Machine Learning Data Set
Unstructured machine learning data set lacks a predefined data model and do not conform to a rigid structure like structured data sets. Examples of an unstructured machine learning data set include text, images, audio, and video files. An unstructured machine learning data set is more challenging to analyze using traditional methods due to its lack of clear organization and standardized format.
Application
- Natural Language Processing (NLP): Unstructured machine learning data set is prevalent in applications such as sentiment analysis, language translation, and chatbots.
- Computer Vision: Unstructured image and video data are essential for tasks like image recognition, object detection, and facial recognition.
Time-Series Machine Learning Data Set
Time-series machine learning data set consists of sequential data points ordered over time. Each data point is associated with a specific timestamp, making time an integral part of the dataset. Time-series data is relevant for understanding how phenomena evolve over time and is commonly used in forecasting and trend analysis.
Examples
- Stock Prices: Analyzing historical stock prices to predict future market trends.
- Weather Data: Studying past weather patterns to forecast future climate conditions.
- Sensor Readings: Monitoring and predicting equipment performance based on time-stamped sensor data.
Challenges in Working with A Machine Learning Data Set
Working with a machine learning data set presents several challenges that can impact the performance and reliability of models. Addressing these challenges is crucial for building accurate and robust machine learning applications. Here are some common challenges associated with machine learning data set:
Data Quality Challenges
The quality of a machine learning model is only as good as the data it learns from. Incomplete, inaccurate, or biased data can significantly hinder model performance. Incompleteness introduces gaps in information, inaccuracy leads to erroneous patterns, and bias can perpetuate unfair predictions. Recognizing and addressing these issues is vital for building reliable and ethical machine learning models.
Data Quantity Challenges
Overfitting occurs when a model learns the training data too well, capturing noise and outliers rather than the underlying patterns. This phenomenon is especially prevalent when the amount of data is limited. Sufficient data is crucial for preventing overfitting, allowing the model to generalize well to unseen instances. Balancing the complexity of the model with the available data is a delicate challenge.
To overcome data quantity challenges, strategies for gathering and augmenting data come into play. Gathering more diverse and representative data is one approach. Additionally, data augmentation techniques, such as introducing variations or synthetic data, can help expand the training set. These strategies aim to provide the model with a richer set of examples, fostering better generalization.
Data Privacy and Security
Many machine learning data set applications involve sensitive information, such as personal or medical data. Handling this information responsibly is a critical aspect of ethical machine learning. Unauthorized access or misuse of sensitive data can have severe consequences, including data privacy violations and legal repercussions.
Addressing these challenges is fundamental to unlocking the full potential of a machine learning data set. In the next section, we will talk about the best practices for working with a machine learning data set, emphasizing strategies to overcome these challenges and optimize the utilization of data for model training and validation.
Machine Learning Data Set Best Practices
Implementing best practices in managing a machine learning data set is crucial for ensuring the success and reliability of models. Here are key best practices:
Aligning Machine Learning Data Set with Project Goals
The first step in working with a machine learning data set is aligning them with the specific goals and requirements of the project. Understanding the nuances of the problem being addressed ensures that the data collected is relevant and directly contributes to the success of the machine learning model. A clear alignment between machine learning data set and project objectives lays the foundation for meaningful insights and accurate predictions.
Data Splitting
To evaluate the performance of a machine learning data set model accurately, data sets should be divided into distinct subsets for training, validation, and testing. The training set is used to train the model, the validation set is used to fine-tune parameters and prevent overfitting, and the test set is reserved for assessing the model’s performance on unseen data. This division ensures a robust evaluation and prevents models from memorizing specific examples.
Feature Engineering
Feature engineering involves the creation of new features or the transformation of existing ones to enhance the predictive power of machine learning data set models. Thoughtful feature engineering can uncover hidden patterns in the data, providing the algorithm with additional information to make more accurate predictions. This process requires domain expertise and a deep understanding of the problem being addressed.
Updating and Monitoring Data Sets for Adaptability
Continuous monitoring of a machine learning data set involves regularly updating and adapting data sets to reflect changes in the environment, user behavior, or other relevant factors. This practice ensures that machine learning models remain relevant and effective in the face of shifting conditions.
Machine Learning Data and NetNut Proxy Servers
Building a successful machine learning model begins with quality data sets. For this process, you can utilize NetNut, an industry leading proxy service provider. With its robust proxy network, NetNut facilitates the seamless collection of diverse and reliable data. We offer rotating residential proxies, which ensures that machine learning data set practitioners have access to a rich and varied dataset, enhancing the model’s ability to generalize and make accurate predictions across different scenarios.
This proxy network has proven effective in resolving some major challenges. This includes;
- NetNut’s Contribution to Data Quality Challenges: NetNut contributes significantly by providing a reliable and secure proxy network. In addition, our proxies ensure that data collected is not only comprehensive but also representative of real-world conditions.
- Data Diversity: Data diversity is paramount for building models that can handle the complexity of real-world scenarios. NetNut’s proxy network, spanning diverse geographical locations and IP addresses, contributes to creating data sets that encapsulate a broad range of perspectives. This diversity is key to training models that can adapt to various contexts, making predictions that are robust and reliable.
By adhering to these best practices, users can optimize the utilization of a machine learning data set, enhance model performance, and ensure the continued relevance and accuracy of their applications.
Conclusion
A machine learning data set serves as the fertile ground where algorithms learn, adapt, and evolve. The impact of a machine learning data set extends far beyond the realm of individual models and applications. Their collective influence shapes the trajectory of artificial intelligence itself. From healthcare to finance, and ecommerce, to mention but a few.
As technology advances, the union between algorithms and data sets propels us toward new frontiers of innovation. The transformative potential of artificial intelligence unfolds as we grapple with increasingly complex problems, and the role of well-constructed data sets becomes even more pivotal in navigating this technological frontier.
Through this recognition, we propel ourselves into a future where the potential of a machine learning data set knows no bounds. There is no limit to how much users
Frequently Asked Questions And Answers
Why is machine learning data set essential for model training?
A machine learning data set is crucial as they provide the examples and patterns that algorithms learn from, enabling accurate predictions and improved model performance.
How do data quality challenges impact a machine learning data set?
Incomplete, inaccurate, or biased data can hinder machine learning data set accuracy. Cleaning and preprocessing are vital to address data quality challenges and ensure reliable predictions.
How does NetNut contribute to the power of a machine learning data set?
NetNut enhances a machine learning data set by providing a reliable and diverse proxy network, ensuring seamless and accurate data collection for robust model training. Data splitting, a crucial step for model evaluation, is enhanced with NetNut’s ability to provide a large pool of IPs, ensuring unbiased and objective assessments.






