Introduction
In the world of professional networking and recruitment, LinkedIn has emerged as a pivotal platform connecting millions of professionals worldwide. With its extensive user base and comprehensive profiles, LinkedIn serves as a goldmine for individuals and businesses seeking to expand their professional networks or identify potential candidates for recruitment.
As the importance of LinkedIn continues to grow, the need to harness its data efficiently becomes imperative. In the context of LinkedIn, web scraping LinkedIn profiles with Python activity becomes a powerful tool for automating the extraction of valuable data from user profiles. This data may include details such as names, job titles, companies, skills, and educational backgrounds.
By automating this web scraping LinkedIn profiles with Python process, individuals and organizations can save time and resources while gaining access to a wealth of information for networking, recruitment, and strategic decision-making. However, there is a need to fully understand how web scraping LinkedIn profiles with Python process can be automated professionally.
Here, we will discuss the in-depth use of Python in LinkedIn data scraping. More so, the smooth integration of Python with libraries like BeautifulSoup and Selenium.
Let’s dive in!
Understanding web scraping LinkedIn profiles with Python Automation

Web scraping, also known as web harvesting or web data extraction, is the automated process of extracting information from websites. It involves sending requests to web pages, retrieving the HTML content, and then parsing and extracting relevant data. While web scraping offers powerful capabilities, it is essential to approach it with ethical considerations during web scraping Python activity.
LinkedIn, like many other websites, has specific terms of service that users must adhere to before web scraping LinkedIn profiles with Python automation. These terms often include restrictions on automated access to their platform.
Therefore, it is crucial for individuals and developers to be aware of and comply with LinkedIn’s policies when engaging in web scraping LinkedIn profiles with Python activities. Violating these terms not only risks legal consequences but also undermines the trust and integrity of the platform.
Setting Up the Development Environment For web scraping LinkedIn profiles with Python
Setting up the development environment for web scraping LinkedIn profiles with Python involves installing essential tools and libraries. Here are the step-by-step guide to help you get started with the necessary components for web scraping LinkedIn profiles with Python .
- Installing Python: Start by downloading the latest version of Python from the official website (https://www.Python.org/). Follow the installation instructions for your operating system. During installation, make sure to check the box that says “Add Python to PATH” for easy command-line access.
- Choosing a Code Editor: Selecting a suitable code editor is crucial for an efficient web scraping LinkedIn profiles with Python development experience. Popular choices include Visual Studio Code, PyCharm, and Jupyter Notebooks. Download and install your preferred code editor according to your operating system.
- Installing Required Libraries: Two essential libraries for web scraping LinkedIn profiles with Python are BeautifulSoup and Selenium. Open a command prompt or terminal window and use commands to install these libraries:
- BeautifulSoup – Parsing HTML: BeautifulSoup is a Python library that provides tools for web scraping LinkedIn profiles with Python content- HTML and XML content. It helps parse HTML documents, navigate the HTML tree structure, and extract relevant information. This means that, after retrieving HTML content from a LinkedIn profile page, BeautifulSoup allows you to search for specific HTML elements containing the data you want to extract. It simplifies the process of locating and isolating desired information.
- Selenium – Automation and Interaction: Selenium is a powerful tool for automating the extraction of data from LinkedIn profiles with Python. It allows you to control a web browser with a program. This makes it particularly useful for scenarios where websites use JavaScript to load dynamic content. Selenium can be integrated into your Python script for web scraping to automate tasks such as logging into LinkedIn, navigating through profiles, and interacting with dynamic elements. It provides the capability to simulate user actions, ensuring a seamless scraping process.
- Integrating Libraries into Your Python Script: In your web scraping Python script, import the necessary libraries at the beginning of your code. After the importation, configure the web driver for Selenium. You can use BeautifulSoup and Selenium functions in tandem to navigate, locate elements, and extract data from LinkedIn profiles.
- Testing Your web scraping LinkedIn profiles with Python Setup: To run this test, create a simple script that opens a LinkedIn profile, retrieves basic information, and prints it to the console. Run the script to ensure that Python, BeautifulSoup, and Selenium are properly configured and working together.
By following these steps, you’ll have a well-established development environment equipped with the necessary tools and libraries to begin scraping LinkedIn profiles with Python.
Using BeautifulSoup for Web Scraping LinkedIn Profiles With Python- HTML Parsing
BeautifulSoup, a Python library, is a powerful tool for parsing HTML and XML content. It simplifies the process of navigating through HTML documents, searching for specific tags, and extracting relevant information. Let’s explore the functionalities of BeautifulSoup and provide a guide on how to locate and extract specific information for web scraping LinkedIn profiles with Python using this versatile library.
- Parsing HTML: Use BeautifulSoup to parse the HTML content retrieved from a LinkedIn profile page during web scraping LinkedIn profiles with Python activity. This creates a BeautifulSoup object, enabling you to navigate and manipulate the HTML.
- Navigating the HTML Tree: BeautifulSoup allows you to navigate the HTML tree using various methods. The most common ones include ‘find()’, ‘find_all()’, and navigating through tag names and attributes.
- Accessing Tag Attributes and Text: Extract attributes or text content from HTML elements using BeautifulSoup.
This process showcases how BeautifulSoup simplifies the process of navigating HTML documents and extracting specific information for web scraping LinkedIn profiles with Python .
Using Selenium for Dynamic web scraping LinkedIn profiles with Python Content
In web scraping, certain websites, including LinkedIn, utilize JavaScript to load dynamic content. While BeautifulSoup is excellent for parsing static HTML, it may fall short when dealing with elements rendered dynamically. This is where Selenium, a powerful web scraping Python automation tool, comes into play.
Selenium is widely used for automating web scraping activities. It allows you to control a web browser, navigate through pages, interact with elements, and handle dynamic web scraping for LinkedIn profiles with Python.
Selenium is particularly valuable when web scraping involves JavaScript-driven interactions that are not captured by traditional HTML parsing. To ensure a comprehensive extraction of data during scraping LinkedIn profiles with Python, Selenium can be used in conjunction with BeautifulSoup to interact with and capture loaded content.
Considerations before using Selenium with BeautifulSoup for web scraping LinkedIn profiles with Python
Before setting up Selenium with BeautifulSoup library for web scraping, consider these actions:
- Ensure that you have the appropriate web driver (e.g., chromedriver) downloaded and its path specified in the webdriver.Chrome() function.
- Adjust the waiting time (time.sleep()) based on the speed of your internet connection and the time required for dynamic content to load.
These considerations aid smooth integration of Selenium with BeautifulSoup, allowing for a holistic approach to scraping LinkedIn profiles with Python.
How To Store Scraped Data After web scraping LinkedIn profiles with Python
Once you’ve successfully web scraping LinkedIn profiles with Python , the next crucial step is to store that data in a structured and manageable format. Here, we’ll discuss various options for storing the collected data after web scraping LinkedIn profiles with Python , such as using CSV files, databases, and more.
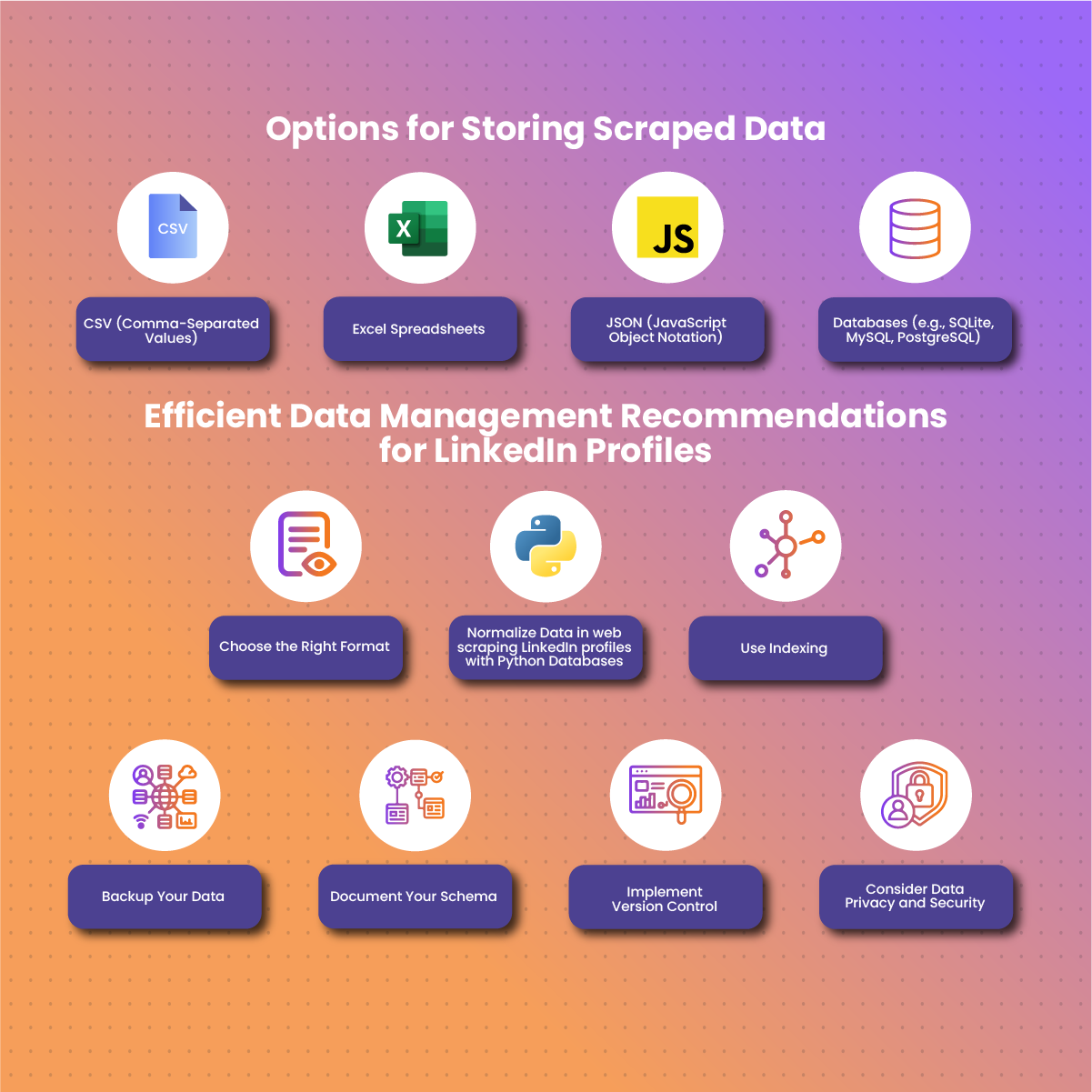
Options for Storing Scraped Data
Here are some formats for saving the scraped data from web scraping LinkedIn profiles with Python :
- CSV (Comma-Separated Values): CSV files are a simple and widely-used format for storing tabular data. Each line in the file represents a row, and the values within each line are separated by commas. One advantage is that they are easy to generate, human-readable, and compatible with various data analysis tools. However, they are limited in terms of data complexity and relationships.
- Excel Spreadsheets: Excel files (.xlsx) can be used for storing data obtained via Python from scraping LinkedIn profiles in tabular form, similar to CSV files. They support multiple sheets and formatting options for storing data obtained from scraping LinkedIn profiles. In addition, they are familiar to many users, easy to open and view, and suitable for small to medium-sized datasets. However, they may not be efficient for very large datasets due to limited scalability.
- JSON (JavaScript Object Notation): JSON is a lightweight data interchange format that is easy for both humans to read and write and easy for machines to parse and generate. It supports complex nested data from scraping LinkedIn profiles. In addition, it is flexible, and widely used in web applications. However, it can be less efficient for tabular data compared to CSV or databases.
- Databases (e.g., SQLite, MySQL, PostgreSQL): Databases provide a structured and scalable way to store data extracted from LinkedIn profiles with Python. They allow for efficient querying, indexing, and relational data modeling. Unfortunately, they may require more setup and maintenance compared to flat files.
Recommendations For Efficient Data Management of Data from LinkedIn Profiles
For effective data management, consider these actions:
- Choose the Right Format: Select a storage format based on the nature and size of the data you want to collect from LinkedIn profiles with Python. For smaller, structured data, CSV or Excel may suffice, while larger and more complex datasets may benefit from a database.
- Normalize Data in web scraping LinkedIn profiles with Python Databases: If using a relational database, consider normalizing your data to reduce redundancy and improve data integrity. This involves organizing data to minimize duplication and dependency.
- Use Indexing: In scraping LinkedIn profiles via Python, implement indexing on columns frequently used for querying. Indexing improves the speed of data retrieval operations.
- Backup Your Data: Regularly backup your stored data obtained from scraping LinkedIn profiles with Python to prevent loss in case of unexpected events. This is especially important when working with databases where data integrity is critical.
- Document Your Schema: If using a database, document the schema (structure) of your web scraping activities. This documentation helps with understanding the relationships between tables and the types of data stored.
- Implement Version Control: If your dataset evolves over time, consider implementing version control for your data. This allows you to track changes and revert to previous versions if needed.
- Consider Data Privacy and Security: Be mindful of data privacy and security. Ensure that data collected from LinkedIn profiles Python is handled responsibly and comply with relevant regulations.
On a final note, choosing the right storage method for the data you obtained from scraping LinkedIn profiles with Python is crucial for efficient analysis and retrieval.
Optimizing web scraping LinkedIn profiles with Python With NetNut Proxy Service
Web scraping has become an essential tool for extracting valuable information from LinkedIn. However, extracting data from LinkedIn profiles comes with challenges, including legal and ethical considerations, as LinkedIn’s Terms of Service explicitly prohibit automated data collection.
LinkedIn employs various anti-scraping mechanisms, including rate limiting, IP blocking, and bot detection algorithms. To overcome these challenges, using residential proxies becomes a viable solution. NetNut is a residential proxy service that offers a vast pool of real IP addresses sourced from devices around the world.
By routing your web scraping requests through these residential proxies, you can reduce the likelihood of being detected and blocked by LinkedIn’s anti-scraping mechanisms.
Setting Up NetNut Proxy Service For web scraping LinkedIn profiles with Python Automation
Set up and automate LinkedIn profiles scraping with a proxy provider by following these steps:
- Start by creating an account on the NetNut website. Choose a plan that suits your web scraping needs.
- After registering, you’ll receive API credentials. These credentials are essential for authenticating your requests when using NetNut’s residential proxies.
- Install NetNut Python Package. This package is viable for extracting LinkedIn profiles with Python any browser.
- Integrate NetNut’s proxy into your Python script by modifying your web scraping script to use NetNut residential or mobile proxies.
By following these steps, you can fully set up your Python script to scrape LinkedIn profiles with NetNut proxy service. This integration allows you to hide your IP address and enjoy quality web scraping without issues on rate limiting and IP blocking.
Conclusion
Web scraping LinkedIn profiles with Python automation opens up a world of possibilities for professionals, recruiters, and businesses. By automating the extraction of valuable data, you can streamline networking efforts, identify top talent, and gather business intelligence.
However, it’s crucial to approach scraping LinkedIn profiles Python with responsibility, respecting ethical standards and adhering to LinkedIn’s terms of service. As users master the act of using Python to scrape LinkedIn profiles, they gain a powerful tool for enhancing their professional endeavors.
Enjoy scraping LinkedIn profiles by leveraging the potential of Python, BeautifulSoup, Selenium, and NetNut’s residential proxies.
Frequently Asked Questions and Answers
Can I scrape LinkedIn profiles with Python automation undetected?
Yes. Implementing best practices such as integration with NetNut proxy service, rate limiting, delays, and respecting platform guidelines can minimize the risk of being detected.
Is It Necessary To Automate The Login Process For Scraping Linkedin Profiles?
Yes, automating the login process is crucial for accessing LinkedIn profiles that require authentication. Selenium can be used to simulate a login, ensuring a seamless process for authentication of scraping LinkedIn profiles.
What is rate limiting?
Rate limiting is a mechanism used by websites to control the number of requests a user can make in a specific time period. To avoid rate limiting, implement delays in your Python script for scraping LinkedIn profiles. Adhere to the guidelines provided by LinkedIn to maintain a positive experience when scraping LinkedIn profiles.






